



I. Prûˋambule▲
Afin de bien comprendre lãintûˋrûˆt de cette pratique, il vous est vivement conseillûˋ de lire lãarticle dûˋdiûˋ û lãintroduction de RDF [cf. mon article en cours de publication sur dûˋveloppez.com] ainsi quãun autre dãexemple sur FOAF.
Il est vivement conseillûˋ dãavoir quelques notions du modû´le RDF et des requûˆtes standards SQL pour la lecture de cet article.
Note de lãauteurô : dãaprû´s les fiches de travail de Tim BernersãLee, RDF sãaccommode trû´s bien dãune base de donnûˋes relationnelle pour le stockage des donnûˋes. Nous dûˋmontrons une telle symbiose ici.
II. Objectifs▲
- Nous allons sûˋrialiser des donnûˋes stockûˋes dans une base de donnûˋes relationnelle vers une prûˋsentation ô¨ô tripletô ô£ classique, seulement avec SQL.
- Nous allons rûˋaliser lãûˋquivalent dãune jointure entre deux tables et voir lãintûˋrûˆt dãune telle procûˋdure.
III. Prûˋrequis et dûˋmarrage▲
Le code SQL fourni a ûˋtûˋ validûˋ sur un Ubuntu 19.04 et la version 10.3 de MariaDB (paquet par dûˋfaut de la distribution). û noter que sur cette version, certaines fonctions de pivot de table prûˋvues par le langage SQL ne sont pas disponibles directement.
Vous nãavez pas besoin dãautres outils quãune connexion û votre base de donnûˋes, avec des droits de crûˋation et de consultation de tables, de vues et de procûˋdures stockûˋes. Pour un souci de confort, je vous invite û tester les requûˆtes avec PHPMyAdmin ou une interface ûˋquivalente, surtout si vous nãûˆtes pas û lãaise avec les concepts abordûˋs ou les requûˆtes SQL.
Nous admettrons ici que vous avez une base vierge sur laquelle nous allons crûˋer deux tables et les peupler par quelques donnûˋes (le format de la table nãa que peu dãimportance, tant que chaque table dispose dãune clef primaire ou dãun index unique pour une des colonnes).
Table ô¨ô facturesô ô£ô :
-- Version de PHP : 7.2.19-0ubuntu0.19.04.1
SET SQL_MODE = "NO_AUTO_VALUE_ON_ZERO";
SET AUTOCOMMIT = 0;
START TRANSACTION;
SET time_zone = "+00:00";
--
-- Base de donnûˋes : `rdfxml`
--
-- --------------------------------------------------------
--
-- Structure de la table `factures`
--
CREATE TABLE `factures` (
`facture_id` int(11) NOT NULL,
`facture_emission` date DEFAULT NULL,
`facture_reglement` date DEFAULT NULL,
`client_id` int(11) NOT NULL,
`liste_id` int(11) NOT NULL,
`facture_total_ht` decimal(10,2) NOT NULL,
`facture_total_tva` decimal(10,2) NOT NULL,
`facture_total_ttc` decimal(10,2) NOT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
--
-- Dûˋchargement des donnûˋes de la table `factures`
--
INSERT INTO `factures` (`facture_id`, `facture_emission`, `facture_reglement`, `client_id`, `liste_id`, `facture_total_ht`, `facture_total_tva`, `facture_total_ttc`) VALUES(1, '2019-08-01', NULL, 1, 1, '15.00', '3.00', '18.00');
INSERT INTO `factures` (`facture_id`, `facture_emission`, `facture_reglement`, `client_id`, `liste_id`, `facture_total_ht`, `facture_total_tva`, `facture_total_ttc`) VALUES(2, '2019-08-02', '2019-08-03', 1, 2, '8.50', '2.00', '10.50');
--
-- Index pour les tables dûˋchargûˋes
--
--
-- Index pour la table `factures`
--
ALTER TABLE `factures`
ADD PRIMARY KEY (`facture_id`);
--
-- AUTO_INCREMENT pour les tables dûˋchargûˋes
--
--
-- AUTO_INCREMENT pour la table `factures`
--
ALTER TABLE `factures`
MODIFY `facture_id` int(11) NOT NULL AUTO_INCREMENT, AUTO_INCREMENT=3;
COMMIT;Table ô¨ô clientsô ô£ô :
-- phpMyAdmin SQL Dump
-- version 4.8.2
-- https://www.phpmyadmin.net/
--
-- HûÇte : localhost
-- Gûˋnûˋrûˋ le : Dim 11 aoû£t 2019 û 12:23
-- Version du serveur : 10.3.13-MariaDB-2
-- Version de PHP : 7.2.19-0ubuntu0.19.04.1
SET SQL_MODE = "NO_AUTO_VALUE_ON_ZERO";
SET AUTOCOMMIT = 0;
START TRANSACTION;
SET time_zone = "+00:00";
--
-- Base de donnûˋes : `rdfxml`
--
-- --------------------------------------------------------
--
-- Structure de la table `clients`
--
CREATE TABLE `clients` (
`client_id` int(11) NOT NULL,
`client_nom` varchar(255) NOT NULL,
`client_prenom` varchar(255) NOT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
--
-- Dûˋchargement des donnûˋes de la table `clients`
--
INSERT INTO `clients` (`client_id`, `client_nom`, `client_prenom`) VALUES(1, 'Garderon', 'Julien');
--
-- Index pour les tables dûˋchargûˋes
--
--
-- Index pour la table `clients`
--
ALTER TABLE `clients`
ADD PRIMARY KEY (`client_id`);
--
-- AUTO_INCREMENT pour les tables dûˋchargûˋes
--
--
-- AUTO_INCREMENT pour la table `clients`
--
ALTER TABLE `clients`
MODIFY `client_id` int(11) NOT NULL AUTO_INCREMENT, AUTO_INCREMENT=2;
COMMIT;IV. Le format triplet▲
IV-A. Exemple de rûˋsultat▲
Notre objectif est de rûˋcupûˋrer ici un retour de la base qui soit compatible avec le format tripletô : cãest-û -dire ici 3 colonnes (sujet, prûˋdicat, objet). Notre finalitûˋ est ici dãaboutir û un rûˋsultat similaire û ceciô :
SELECT sujet, prûˋdicat, objet FROM `rdf`ô ;
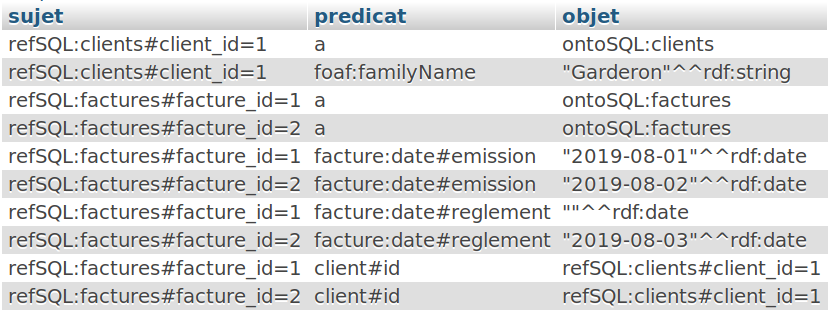 |
Notez que conformûˋment au fonctionnement de RDF, il nãy a plus de notion de ô¨ô clefô ô£ (primaire ou dãindex) dans un tel rûˋsultat qui, dans notre cas, sera sous le format dãune jonction de vues.
IV-B. Le principe▲
Il nãest pas spûˋcialement difficile de passer dãun format relationnel û un format triplet en SQL. Nous utiliserons pour cela la commande UNION ALL, qui permet de regrouper dans un rûˋsultat unique plusieurs requûˆtes de sûˋlection (le nombre de colonnes et leur type doivent ûˆtre identiques).
Exûˋcutez dans votre ûˋditeur la requûˆte suivanteô :
SELECT `facture_id`, 'emission', `facture_emission` FROM `factures`Le rûˋsultat est dûˋjû un simulacre de RDF avec la premiû´re colonne qui serait le sujet (identifiant), la colonne ô¨ô emissionô ô£ qui serait la valeur de relation (prûˋdicat) et le sujet ã en lãoccurrence la date dãûˋmission de la factureô :
|
|

Cãest intûˋressant, mais nous nãavons lû quãune seule colonne pour une table. Exûˋcutez maintenantô :
SELECT `facture_id` AS sujet,
'a' AS predicat,
'sql:factures' AS objet
FROM `factures`
UNION ALL
SELECT `facture_id`,
'emission',
`facture_emission`
FROM `factures`
UNION ALL
SELECT `facture_id`,
'reglement',
`facture_reglement`
FROM `factures`
UNION ALL
SELECT `facture_id`,
'client',
`client_id`
FROM `factures`
UNION ALL
SELECT `facture_id`,
'items',
`liste_id`
FROM `factures`
UNION ALL
SELECT `facture_id`,
'total#ht',
`facture_total_ht`
FROM `factures`
UNION ALL
SELECT `facture_id`,
'total#tva',
`facture_total_tva`
FROM `factures`
UNION ALL
SELECT `facture_id`,
'total#ttc',
`facture_total_ttc`
FROM `factures`;
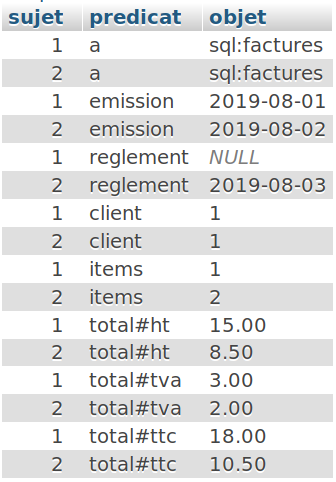 |
Notre retour contient dûˋsormais lãensemble des donnûˋes de la table, dans un format conforme aux triplets. Il reste que notre ontologie (cãest-û -dire la grammaire pour ûˋcrire les triplets et les rendre symboliquement compatibles dans un espace de sens donnûˋ) nãest pas conforme.
De plus, cette ûˋcriture, si elle reste faisable û la main, est loin dãûˆtre efficace pour un grand nombre de tables et cãest une source dãerreur (oubli). Une meilleure solution doit ûˆtre trouvûˋe.
IV-C. Les procûˋduresô : solution A ã sãappuyer exclusivement sur les informations de la table▲
Notre premiû´re solution ne sãappuie que sur les informations dûˋjû contenues dans nos tables. Elle a ma prûˋfûˋrence si derriû´re, le systû´me de traitement est capable de supporter des transformations de triplets ou des infûˋrences afin de rendre conforme lãontologie û celle de lãarchitecture visûˋe.
Nous utiliserons pour cela une procûˋdure stockûˋe, qui produira û partir des informations sur la table visûˋe (grûÂce û INFORMATION_SCHEMA.COLUMNS), une requûˆte de crûˋation de vue. Cãest donc û partir dãune vue de la table, qui est conforme û une prûˋsentation au format triplet, que nous pourrions rûˋaliser des jointures.
DROP
PROCEDURE IF EXISTS `serialiser`;
DELIMITER | CREATE PROCEDURE `serialiser`(
IN table_nom varchar(25),
IN table_colref varchar(25),
IN debug boolean
) BEGINDECLARE stop_curseur_colonnes INT DEFAULT 0;
DECLARE colonne_nom VARCHAR(25);
DECLARE colonne_type VARCHAR(15);
DECLARE `argument_vide` CONDITION FOR SQLSTATE '45000';
DECLARE curseur_colonnes CURSOR FOR
SELECT
COLUMN_NAME,
data_type
FROM
information_schema.columns
WHERE
TABLE_NAME = table_nom;
DECLARECONTINUE HANDLER FOR SQLSTATE '02000'
SET
stop_curseur_colonnes = 1;
DECLARE EXIT HANDLER FOR sqlexceptionBEGIN
SELECT
Concat(
"erreur : la sûˋrialisation a ûˋchouûˋ ('",
@requete, "')."
);
END;
IF table_nom = "" THEN
SET
@requete = "le nom de la table est vide";
SIGNAL `argument_vide`;
ENDIF;
IF table_nom = "" THEN
SET
@requete = "le nom de la colonne identifiante est vide";
SIGNAL `argument_vide`;
ENDIF;
SET
@refSQL = Concat(
'CONCAT( "refSQL:facture#", ', table_colref,
' )'
);
SET
@requete = Concat(
'SELECT ', @refSQL, ' as sujet, "a" as predicat, "ontoSQL:',
table_nom, '" as objet FROM ', table_nom
);
OPEN curseur_colonnes;
REPEATFETCH curseur_colonnes INTO colonne_nom,
colonne_type;
IF stop_curseur_colonnes = 0 THEN
SET
@requete = concat(
@requete, ' UNION ALL SELECT ', @refSQL,
', "ontoSQL:', table_nom, '#', colonne_nom,
'", CONCAT( \'"\', IFNULL( ', colonne_nom,
', "") , \'"^^SQL:', colonne_type,
'\' ) FROM ', table_nom
);
ENDIF;
UNTIL stop_curseur_colonnes END repeat;
IF debug IS FALSE THEN
SET
@requetePrepare = concat(
'DROP VIEW IF EXISTS `rdf_', table_nom,
'`; '
);
PREPARE stmt
FROM
@requetePrepare;
EXECUTE Stmt;
SET
@requeteVue = Concat(
' CREATE VIEW `rdf_', table_nom,
'` AS ', @requete, ' ; '
);
PREPARE stmt
FROM
@requeteVue;
EXECUTE Stmt;
SET
@requeteSelection = concat(
' SELECT * FROM `rdf_', table_nom,
'` ; '
);
PREPARE stmt
FROM
@requeteSelection;
EXECUTE stmt;
DEALLOCATE PREPARE stmt;
END IF;
IF DEBUG IS TRUE THEN
SELECT
@requete;
END IF;
END | DELIMITER;Cette procûˋdure vous permettra de produire une requûˆte (et ûˋventuellement lãexûˋcuter si DEBUG est û false ) qui produira elle-mûˆme une vue conforme û la table. Attention, pour que cette procûˋdure aboutisse et soit ô¨ô logiqueô ô£, il faut que votre sûˋrialisation se produise avec une colonne ô¨ô pivotô ô£ qui est la colonne identifiante (cf. la remarque en prûˋrequis).
call `serialiser`( "factures", "facture_id", FALSE
-- la requûˆte sera exûˋcutûˋe immûˋdiatement
);Vous devriez avoir des retours similaires û ceciô :
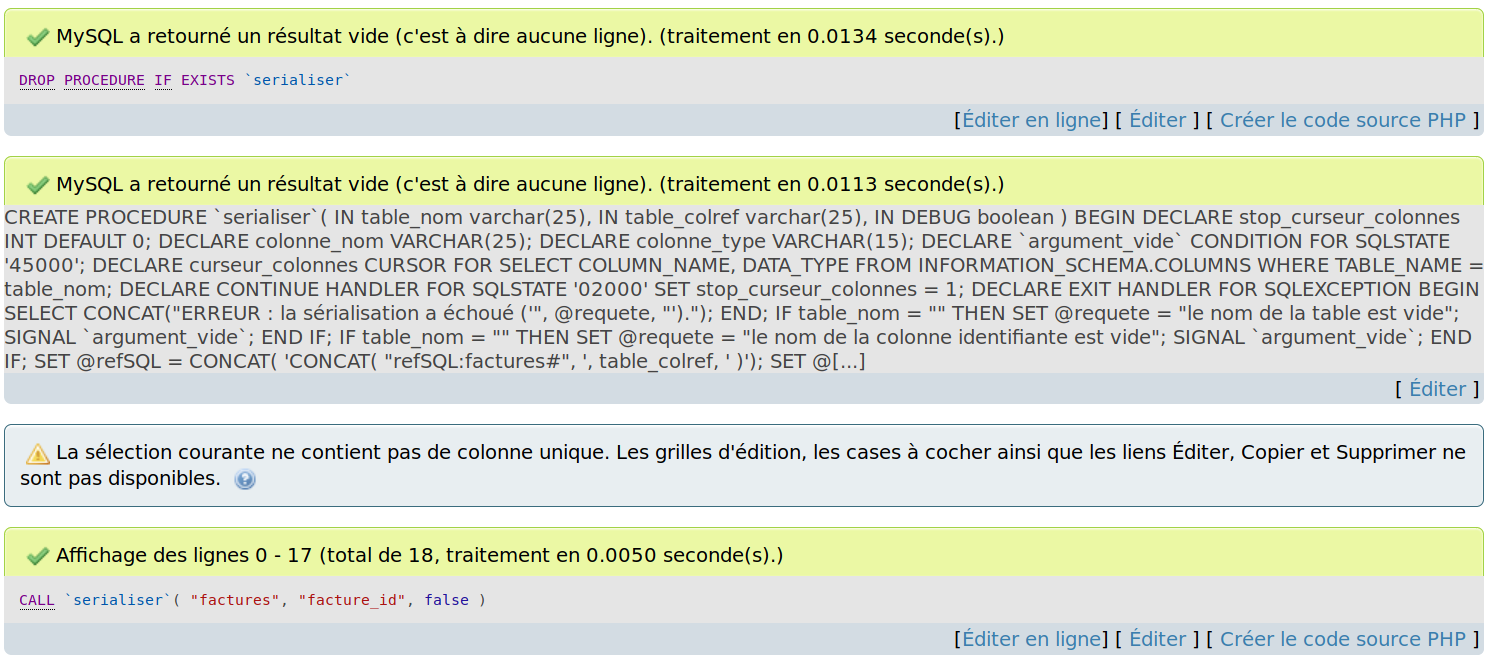 |
Une vue a ûˋtûˋ crûˋûˋe (pensez û recharger la page si vous ûˆtes sous PHPMyAdmin et quãelle nãapparaûÛt pas automatiquement)ô :
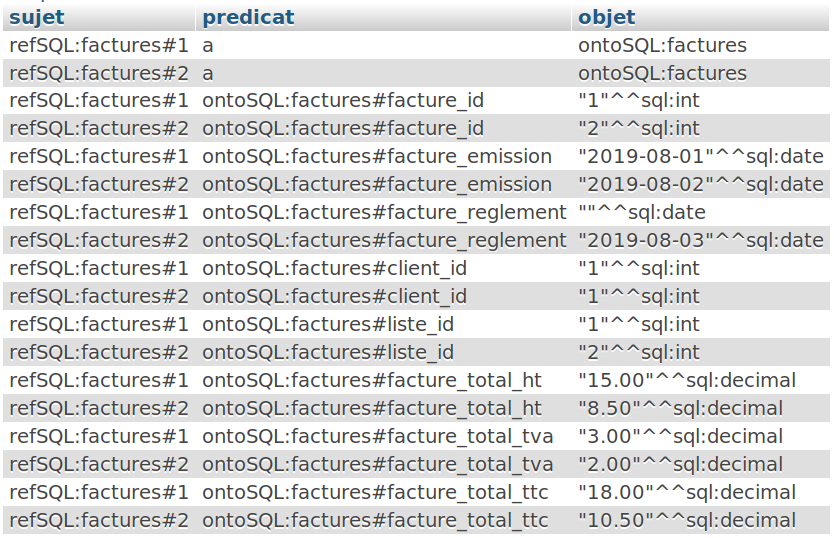 |
Vous noterez dûˋsormais quãil y a une conformitûˋ plus grande des rûˋsultats de la vue avec le modû´le RDF canoniqueô : les valeurs dãobjet indiquent leur type (int , decimal , date , etc.). Les attributs marquûˋs NULL sont traitûˋs ici et affichûˋs comme une date invalide. Nous aurions pu les extraire des rûˋsultats pour respecter une rû´gle de RDF qui indique quãil ne faut normalement pas afficher les colonnes marquûˋes NULL, cependant, ô¨ô lãespritô ô£ de la table est ici dãavoir du sens û une absence de date pour la colonne ô¨ô facture_reglementô ô£ (pas de date = pas de rû´glement).
La colonne des prûˋdicats semble respecter davantage un dûˋbut de grammaire et les sujets, si ce ne sont pas directement des URI, sont des rûˋfûˋrences ô¨ô uniquesô ô£ û la base visûˋe. Le systû´me de traitement peut donc ensuite faire ô¨ô pointerô ô£ correctement une telle rûˋfûˋrence û la donnûˋe concernûˋe.
Nous pourrions nous contenter dãune telle prûˋsentation et rûˋpûˋter la commande de sûˋrialisation pour la table ô¨ô clientsô ô£. Mais peut-ûˆtre y a-t-il une autre solutionô ?
IV-D. Les procûˋduresô : solution B ã respecter une grammaire dûˋfinie▲
Lãintûˋrûˆt de SQL est de dûˋfinir pour chaque colonne un type de valeur bien dûˋfini. Cãest ainsi que dans la solution prûˋcûˋdente, nous avons traitûˋ chaque cellule et produit pour chaque objet des triplets, la valeur et son type.
Cependant, la conformitûˋ nãest pas idûˋale et les formats SQL ne correspondent pas prûˋcisûˋment aux formats RDF. Pireô : le ô¨ô castingô ô£ dãune valeur vers un type string est ici implicite. Ce nãest pas acceptable.
Aussi, nous allons crûˋer dans notre base une nouvelle table qui comportera les colonnes, leur valeur de prûˋdicat et leur valeur dãobjet (avec le type) pour chaque table û sûˋrialiser. Si une colonne nãest pas dûˋfinie dans cet outil de dûˋmarrage dãune ontologie, alors elle ne sera jamais reproduite dans la vue RDF ã logiquement.
Voici la dûˋfinition dãune telle table, appelûˋe ô¨ô ontologiesô ô£ô :
-- phpMyAdmin SQL Dump
-- version 4.8.2
-- https://www.phpmyadmin.net/
--
-- HûÇte : localhost
-- Gûˋnûˋrûˋ le : Dim 11 aoû£t 2019 û 13:44
-- Version du serveur : 10.3.13-MariaDB-2
-- Version de PHP : 7.2.19-0ubuntu0.19.04.1
SET sql_mode = "NO_AUTO_VALUE_ON_ZERO";SET autocommit = 0;START TRANSACTION;SET time_zone = "+00:00";
--
-- Base de donnûˋes : `rdfxml`
--
-- --------------------------------------------------------
--
-- Structure de la table `ontologies`
--CREATE TABLE `ontologies`
(
`onto_id` int(11) NOT NULL auto_increment PRIMARY KEY,
`onto_table` varchar(255) NOT NULL,
`onto_orga` int(3) NOT NULL,INSERT INTO `ontologies`
(
`onto_table`,
`onto_orga`,
`onto_colonne`,
`onto_predicat`,
`onto_masque`
)
VALUES
(
'factures',
1,
'facture_id',
'a',
'refSQL:factures#facture_id=%s'
);INSERT INTO `ontologies`
(
`onto_table`,
`onto_orga`,
`onto_colonne`,
`onto_predicat`,
`onto_masque`
)
VALUES
(
'factures',
2,
'facture_emission',
'facture:date#emission',
'\"%s\"^^rdf:date'
);INSERT INTO `ontologies`
(
`onto_table`,
`onto_orga`,
`onto_colonne`,
`onto_predicat`,
`onto_masque`
)
VALUES
(
'factures',
3,
'facture_reglement',
'facture:date#reglement',
'\"%s\"^^rdf:date'
);INSERT INTO `ontologies`
(
`onto_table`,
`onto_orga`,
`onto_colonne`,
`onto_predicat`,
`onto_masque`
)
VALUES
(
'factures',
4,
'client_id',
'client#id',
'refSQL:clients#client_id=%s'
);INSERT INTO `ontologies`
(
`onto_table`,
`onto_orga`,
`onto_colonne`,
`onto_predicat`,
`onto_masque`
)
VALUES
(
'clients',
1,
'client_id',
'a',
'refSQL:clients#client_id=%s'
);INSERT INTO `ontologies`
(
`onto_table`,
`onto_orga`,
`onto_colonne`,
`onto_predicat`,
`onto_masque`
)
VALUES
(
'clients',
2,
'client_nom',
'foaf:familyName',
'\"%s\"^^rdf:string'
);
--
-- Index pour les tables dûˋchargûˋes
--
--COMMIT;Vous devriez avoir une table avec les valeurs suivantesô :
 |
Notez la colonne ô¨ô onto_orgaô ô£ô : elle permet de ô¨ô classerô ô£ les triplets, mais surtout de dûˋterminer le poids des colonnes. Dans ma logique, la valeur 1 dans cette colonne pour chaque table ûˋquivaut û la colonne de la clef primaire pour la table û sûˋrialiser.
La valeur de prûˋdicat est ici rûˋpûˋtûˋe. Nous aurions pu aussi faire des tables ô¨ô prûˋdicatsô ô£ et ô¨ô masqueô ô£ pour ûˋviter les rûˋpûˋtitions de types ã mais jãai prûˋfûˋrûˋ la simplicitûˋ. Sachez simplement quãici, des jointures pour ûˋviter les doublons seraient prûˋfûˋrables.
Voyons maintenant la procûˋdure de sûˋrialisation modifiûˋe et son exûˋcutionô :
DROP
PROCEDURE IF EXISTS `serialiser`;
DELIMITER | CREATE PROCEDURE `serialiser`(
IN table_nom varchar(255),
IN table_colref varchar(255),
IN debug boolean
) BEGINDECLARE stop_curseur_colonnes INT default 0;
DECLARE colonne_orga INT(3);
DECLARE colonne_nom VARCHAR(255);
DECLARE colonne_relation VARCHAR(255);
DECLARE colonne_masque VARCHAR(255);
DECLARE `argument_vide` condition FOR sqlstate '45000';
DECLARE curseur_colonnes CURSOR FOR
SELECT
onto_orga,
onto_colonne,
onto_predicat,
onto_masque
FROM
ontologies
WHERE
onto_table = table_nom
ORDER BY
onto_orga ASC;
DECLARECONTINUE handler FOR sqlstate '02000'
SET
stop_curseur_colonnes = 1;
DECLARE EXIT HANDLER for sqlexceptionBEGIN
SELECT
Concat(
"erreur : la sûˋrialisation a ûˋchouûˋ ('",
@requete, "')."
);
END;
IF table_nom = "" then
SET
@requete = "le nom de la table est vide";
SIGNAL `argument_vide`;
ENDIF;
IF table_nom = "" then
SET
@requete = "le nom de la colonne identifiante est vide";
SIGNAL `argument_vide`;
ENDIF;
OPEN curseur_colonnes;
REPEATFETCH curseur_colonnes INTO colonne_orga,
colonne_nom,
colonne_relation,
colonne_masque;
IF colonne_orga = 1 then
SET
@refSQL = concat(
'REPLACE( \'', colonne_masque, '\', "%s", ',
table_colref, ' ) '
);
SET
@requete = Concat(
' SELECT ', @refSQL, ' AS sujet, "',
colonne_relation, '" AS predicat, "ontoSQL:',
table_nom, '" AS objet FROM ',
table_nom
);
ENDIF;
IF colonne_orga > 1
AND stop_curseur_colonnes = 0 then
SET
@requete = concat(
@requete, ' UNION ALL SELECT ', @refSQL,
', "', colonne_relation,
'", REPLACE( \'', colonne_masque,
'\', "%s", IFNULL( CAST( ', colonne_nom,
' AS CHAR CHARACTER SET utf8 ), "" ) ) FROM ',
table_nom
);
ENDIF;
UNTIL stop_curseur_colonnes END repeat;
IF debug IS false THEN
SET
@requetePrepare = concat(
'DROP VIEW IF EXISTS `rdf_', table_nom,
'`;'
);
PREPARE stmt
FROM
@requetePrepare;
EXECUTE Stmt;
SET
@requeteVue = Concat(
' CREATE VIEW `rdf_', table_nom,
'` AS ', @requete, ' ; '
);
PREPARE stmt
FROM
@requeteVue;
EXECUTE Stmt;
SET
@requeteSelection = Concat(
' SELECT * FROM `rdf_', table_nom,
'` ; '
);
PREPARE stmt
FROM
@requeteSelection;
EXECUTE Stmt;
DEALLOCATE prepare stmt;
ENDIF;
IF debug IS true THEN
SELECT
@requete;
ENDIF;
END | delimiter;
CALL `serialiser`("factures", "facture_id", false);Votre retour devrait ûˆtre similaire û ceciô :
|
|
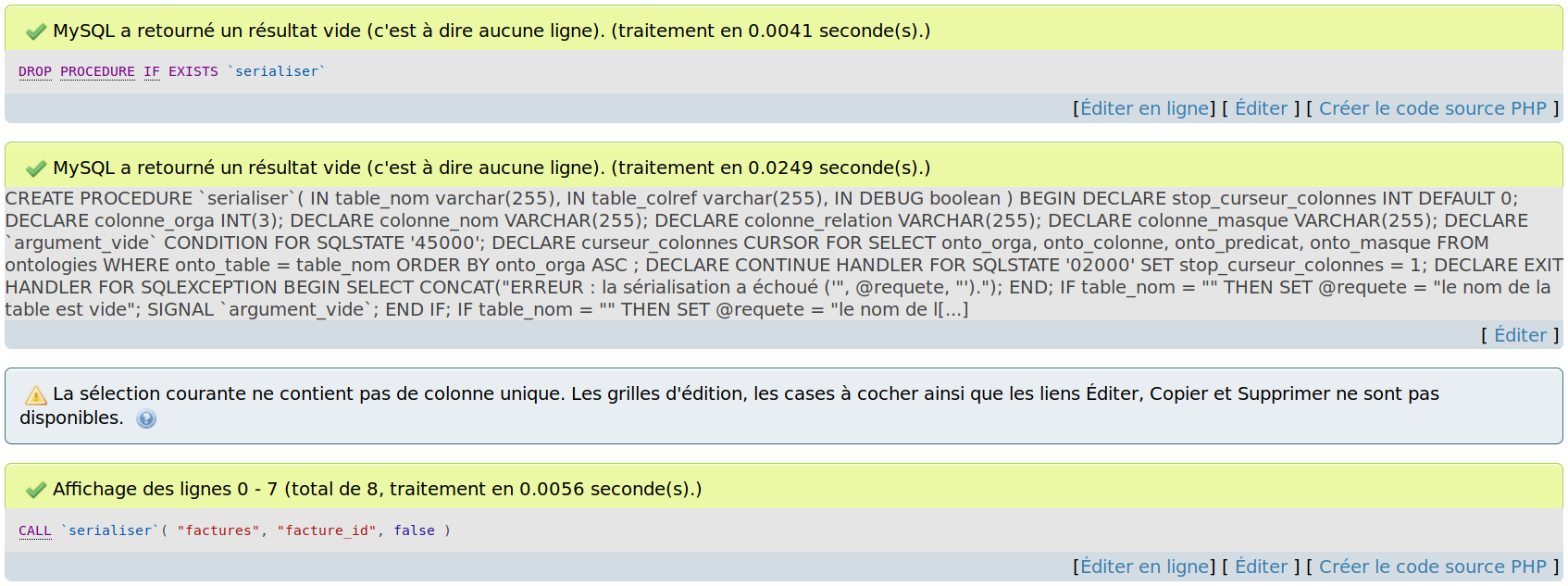
La vue pour les factures ô¨ô rdf_factureô ô£ devrait ûˆtre mise û jour comme suitô :
Pensez û exûˋcuter la sûˋrialisation pour la table ô¨ô clientsô ô£ô :
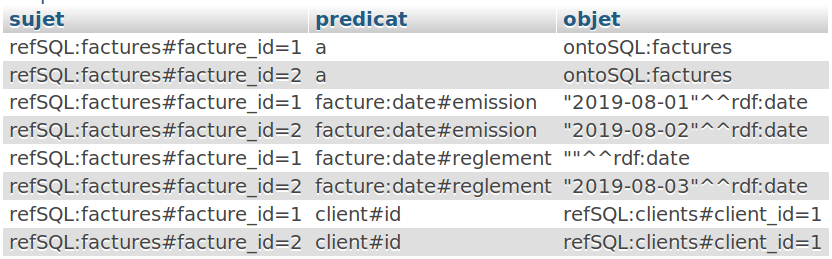 |
CALL `serialiser`( "clients", "client_id", false )ô ;IV-E. La jointureô : rûˋalisation▲
Nous avons maintenant deux vues, lãune pour la table ô¨ô facturesô ô£ et lãautre pour la table ô¨ô clientsô ô£. Pour lãamusement, vous pouvez aussi produire une vue de la table ô¨ô ontologiesô ô£, en pensant û ajouter les lignes correspondantesãÎ
Nous allons produire maintenant une vue des vues disponibles, qui nous sera comme ô¨ô base RDFô ô£ô :
CREATE view `rdf`
AS
SELECT *
FROM rdf_clients
UNION ALL
SELECT *
FROM rdf_factures;Ainsi, nous avons dûˋsormais une vue unique ô¨ô rdfô ô£ qui peut ûˆtre appelûˋe et requûˆtûˋe, avec seulement les colonnes sûˋlectionnûˋes dans la table ô¨ô ontologiesô ô£ et une grammaire respectueuse de RDFô :
|
|
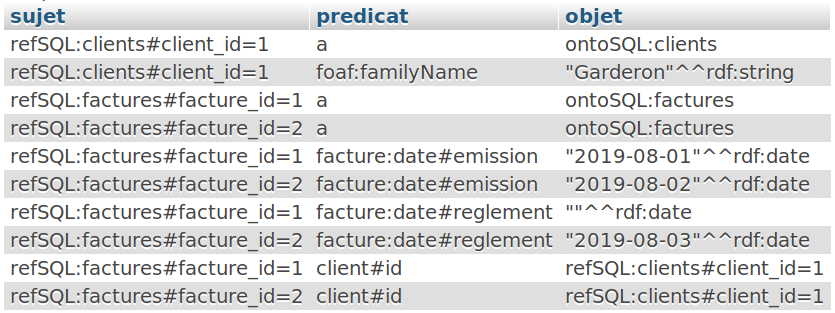
Vous pouvez vûˋrifier en modifiant une valeurô : votre vue basûˋe sur une table SQL qui pourrait ûˆtre en production est tout û fait conforme et reprend bien les valeurs dãorigine.
Notre prochaine ûˋtape sera une jointure afin de rûˋcupûˋrer la facture nô¯1 avec les informations disponibles au format RDF du client.
Testez une premiû´re requûˆte pour saisir le principe que je vais dûˋvelopper aprû´sô :
SELECT *
FROM rdf
WHERE ( sujet LIKE 'refSQL:clients#client_id=1%'
OR objet LIKE 'refSQL:clients#client_id=1%' );Le rûˋsultat montre bien quelques informations qui correspondent û notre factureô :

Pour renvoyer toutes les informations disponibles, il faut comprendre que la ô¨ô jointureô ô£ se fera en prenant lãidentifiant RDF de la facture et lãidentifiant RDF du client. Et ûˋventuellement des autres tables qui pourraient ûˆtre concernûˋesãÎ
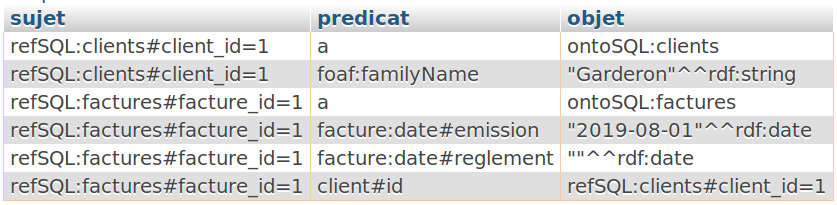
Voici une telle requûˆte, qui pourrait facilement ûˆtre incorporûˋe dans une autre procûˋdure stockûˋe ou une fonctionô :
SET @refSQL = "refsql:factures#facture_id=1";
SET @refJointure = "client#id";
SELECT *
FROM rdf
WHERE sujet = @refSQL
UNION ALL
SELECT *
FROM rdf
WHERE sujet = (SELECT objet
FROM rdf
WHERE sujet LIKE @refSQL
AND predicat LIKE @refJointure);La rûˋfûˋrence de la jointure entre les factures et les clients est donc un prûˋdicat hûˋritûˋ de notre ontologieô : client#id (cãest-û -direô : ô¨ô la propriûˋtûˋ Identifiant du concept de Clientô ô£). Son exûˋcution nous renvoie parfaitement les donnûˋes disponibles suivant ce qui a ûˋtûˋ spûˋcifiûˋ dans la table ô¨ô ontologiesô ô£ô :
IV-F. La question des performances et de la sûˋcuritûˋô ?▲
Pour la partie ô¨ô sûˋcuritûˋô ô£, vous pouvez ajuster les droits afin de faire correspondre les vues produites û un profil particulier, qui nãaura donc que lãaccû´s (en lecture) aux donnûˋes qui correspondent û ce qui est dûˋfini dans la table ô¨ô ontologiesô ô£ - cãest donc plutûÇt un progrû´s, car vous choisissez trû´s finement lãaccû´s, colonne par colonne, pour chaque table sûˋrialisûˋe.
De plus, si vous modifiez lãorganisation de vos tables, lãappel û la fonction de sûˋrialisation modifie û la volûˋe votre vue RDF de la table ã cãest donc faisable ô¨ô û chaudô ô£ avec une gestion intelligente des verrous.
Sur la question des performances, lors que les jointures sont nombreuses et les tables importantes, la notion de produits cartûˋsiens ã une ûˋpreuve mortelle pour votre base dans certains cas ã se traite ici diffûˋremment. û proprement parler, il nãy a pas de produit cartûˋsien, car nous ne sommes que sur une imbrication de requûˆtes de sûˋlection. Parler de jointure serait donc impropre, mais lãidûˋe, le rûˋsultat, cãest dãavoir les mûˆmes informations disponibles que dans une jointure SQL classique.
Enfin, lãusage ô¨ô union allô ô£ ûˋvite un traitement des doublons (peu importe leur existence). Lãusage des vues ûˋvite le peuplement de tables temporaires. Ce que je propose ici est donc probablement lãune des voies les plus efficaces pour sûˋrialiser des tables en SQL vers des triplets RDF exploitables par un moteur dûˋdiûˋ, en utilisant les possibilitûˋs offertes nativement par SQL.
Reste que cet usage nãest pas recommandûˋ pour un grand nombre de donnûˋes, car la gûˋnûˋration de la vue nãest pas neutre en termes de dûˋlai (jusquãû plusieurs secondes).
Cependant, il reste des points dãamûˋlioration, en jouant justement sur des tables de rûˋsultats. Ainsi, des tests avec les requûˆtes sur un ensemble de donnûˋes plus massif (145 k entrûˋes, avec une dizaine de colonnes) renvoient des milliers de lignes (145 k triplets pour chaque colonne de la table SQLãÎ).
Le temps de traitement sur la vue, sans jointure, avoisine alors 4.5 secondes (au lieu de 0.26 seconde avec une requûˆte simple) et nãûˋvolue pas, quel que soit le nombre de traitements ou de recherches appliquûˋs. Dans la plupart des cas, cãest un dûˋlai inacceptable.
Une idûˋe pour optimiser cela est lãutilisation dãune table pour stocker les donnûˋes extraites (ce qui en rûˋduit souvent le nombre), les sûˋrialiser, puis les renvoyer (attention, la base est diffûˋrente de celle indiquûˋe plus haut, pour lãexemple)ô :
CREATE TABLE vers_rdfSELECT *
FROM `lexique`
WHERE `lemme` = 'zyeuter' ; -- cette requûˆte retourne 8 ûˋlûˋments de la table d'origine "lexique"CREATE VIEW rdf_vers_rdf AS
SELECT Replace( 'refSQL:lexique#lexique_id=%s', "%s", lexique_id ) AS sujet,
"a" AS predicat,
"ontoSQL:lexique" AS objet
FROM vers_rdf
UNION ALL
SELECT Replace( 'refSQL:lexique#lexique_id=%s', "%s", lexique_id ) ,
"lexique:orthographe",
replace( '"%s"^^rdf:string', "%s", ifnull( cast( ortho AS char characterSET utf8 ), "" ) )
FROM vers_rdf
UNION ALL
select replace( 'refSQL:lexique#lexique_id=%s', "%s", lexique_id ) ,
"lexique:lemme",
replace( '"%s"^^rdf:string', "%s", ifnull( cast( lemme AS char characterSET utf8 ), "" ) )
FROM vers_rdf
UNION ALL
select replace( 'refSQL:lexique#lexique_id=%s', "%s", lexique_id ) ,
"lexique:type",
replace( '"%s"^^rdf:string', "%s", ifnull( cast( cgram AS char characterSET utf8 ), "" ) )
FROM vers_rdf ; -- cette requûˆte peut ûˆtre gûˋnûˋrûˋe par une procûˋdure, en utilisant les briques de la procûˋdure "sûˋrialiser" dûˋjû indiquûˋeSELECT *
FROM rdf_vers_rdf ; -- retourne les rûˋsultatsDROP TABLE vers_rdf;DROP VIEW rdf_vers_rdf;Lãensemble des dûˋlais cumulûˋs pour ces opûˋrations, tombe alors û 0.2844 seconde, proche dãune requûˆte SQL classique, en gardant la souplesse de RDF.
Si vous avez encore des doutes sur les performances globales du modû´le RDF (au-delû du cas que jãûˋvoque ici, qui sãapparente û un cas dãûˋtude), je vous invite û lire lãintroduction sur le Web Data du W3Cô :
|
Data is increasingly important to society and W3C has a mature suite of Web standards with plans for further work on making it easier for average developers to work with graph data and knowledge graphs. Linked Data is about the use of URIs as names for things, the ability to dereference these URIs to get further information and to include links to other data. There are ever increasing sources of Linked Open Data on the Web, as well as data services that are restricted to the suppliers and consumers of those services.
|
Les donnûˋes sont de plus en plus importantes pour la sociûˋtûˋ et le W3C dispose d'une suite de normes Web bien prûˋparûˋe, qui devrait permettre aux dûˋveloppeurs moyens de travailler plus facilement avec les donnûˋes graphiques et les graphiques de connaissances. Les donnûˋes liûˋes concernent l'utilisation des URI en tant que noms d'objets, la possibilitûˋ de dûˋrûˋfûˋrencer ces URI pour obtenir des informations supplûˋmentaires et d'inclure des liens vers d'autres donnûˋes. Il existe de plus en plus de sources de donnûˋes ouvertes liûˋes sur le Web, ainsi que de services de donnûˋes rûˋservûˋs aux fournisseurs et aux consommateurs de ces services.
|
V. Conclusions▲
Ce que jãexplique ici est une premiû´re approche de ce que peut faire une application de SQL pour la production RDF dans des bases relationnelles.
Pour tester des scûˋnarios et des dûˋveloppements, ou une production sûˋmantique sur peu de tables ou peu de donnûˋes par table, une telle solution suffit largement.
Si vous connaissez de meilleures mûˋthodes que celle que jãai dûˋmontrûˋe ici, discutons-en sur le forumô !
û trû´s bientûÇt.
VI. Note de la rûˋdaction de Developpez.com▲
Nous tenons û remercier escartefigue pour la relecture orthographique de ce tutoriel.