



I. Préalable▲
Avant de commencer cet article, je vous recommande tout particulièrement de lire les deux parties précédentes. En effet nous n’aborderons pas ici la question de la représentation de l’information, ses possibles et souhaitables, ni le fonctionnement des échanges ou l’explication des termes utilisés. Cet article veut se consacrer uniquement sur la théorie du RDF et sur son intérêt. Les prérequis techniques sont considérés comme tout à fait acquis.
Cette chronique s’intéressera prioritairement à des aspects davantage méthodologiques et d’usage et à ce qui a conduit à la création de RDF.
II. Aux origines▲
Avec une brillante équipe constituée progressivement, le père de RDF est un illustre personnage de l’informatique : Tim Berners-Lee, l’inventeur principal du « Web » comme de nombreux concepts et de leur application. Parmi ces inventions, citons la mise en œuvre de l’hypertexualité au sein des documents Internet, créée par Ted Nelson en 1965, c’est-à-dire le lien d’un texte vers un autre ; la première version du protocole HTTP, la représentation graphique d’informations avec HTML ; le premier client et serveur du Web tout comme la notion d’adresse humainement compréhensible.
Au CERN, le Web, dès l’origine entre 1989 et 1992, tentait de répondre à un enjeu simple : rendre facilement accessible l’information échangée entre deux postes sans se préoccuper des couches techniques. N’oubliez pas qu’à l’époque, le protocole HTTP n’existait qu’au format brouillon (à peine plus qu’une idée). En somme, Tim Berners-Lee n’a pas inventé Internet, mais les conditions de son utilisation à vocation humaine facile et universelle, rien que ça !
Rendre facilement accessible, c’est donc uniformiser l’échange et la représentation d’une information entre destinataire et émetteur. Cette représentation, comme nous le verrons plus loin, n’est pas qu’une affaire de modalités techniques, mais aussi conceptuelles.
Pour l’instant, cette uniformisation n’est jamais en définitive qu’un standard industriel (industrie de l’informatique) devenu une norme plus large. Cette norme est elle-même devenue un concept de gestion documentaire et une appréhension, une vision du monde. Le travail de Tim Berners-Lee a modifié une organisation technique et ses conséquences humaines.
Si le Web a répondu à l’époque si bien aux besoins des chercheurs, ingénieurs ou universitaires, c’est qu’ils ne se préoccupaient plus du comment : ces derniers accédaient « instantanément » à la donnée utile, dans un format bien plus agréable et pratique qu’un « amas de texte » (l’équivalent d’une feuille de papier au format numérique). Le principe du Web est d’introduire et normaliser l’interactivité, c’est-à-dire la possibilité d’accéder à une autre ressource à partir d’une première, grâce à une action simple (un clic par exemple). Une idée révolutionnaire qui a été étendue au sein du « navigateur » (un agent), plus tard, avec le célèbre et décrié langage JavaScript, afin que cette interactivité progresse.
L’interactivité se fait entre l’humain et la machine, elle-même en lien avec le réseau. La machine, l’agent, n’est pas donc absente de la relation, et le Web a été conçu aussi pour que cet agent, à terme, puisse aider bien davantage l’humain.
Très vite – très probablement dès l’origine –, les faiblesses du Web sont apparues. Moins de 3 ans après l’invention officielle du Web, Tim Berners-Lee s’intéressait aux limites déjà atteintes d’un Web « capharnaüm » (l’entropie!). Il relevait ce que les machines ne comprenaient pas (la compréhension du langage humain n’est pas leur vocation première !) : ce qui est adapté à l’homme n’est pas nécessairement adapté à la machine, notamment sur les aspects symboliques du texte et donc de toutes les données alors présentes (même une simple date ou un nombre ne peut être conçu comme autre chose qu’une chaîne de caractère si le programmeur ou l’utilisateur ne l’indique pas). Les premiers moteurs de recherche sont alors des annuaires et des systèmes de mots-clefs, peu aboutis : l’information est certes facilement accessible, mais encore faut-il la trouver, et les notions de référencement, la qualité de celui-ci, restent médiocres.
L’humain est essentiel pour « tisser » et parcourir le réseau de contenus et de liens. Pour produire une culture, le Web est laborieux au sens premier du terme, avant la révolution mécanique : il nécessite le labour de l’homme.
Ce qui sera appelé bientôt comme le « Web Sémantique » (ou en des termes plus commerciaux Web 3.0, le Web 2.0 étant une évolution plus technique sur les performances et les modalités d’échanges), n’est qu’une évolution naturelle et finalement originelle du Web. C’est une évolution voulue par ses concepteurs et qui est utilisée désormais d’une manière parfois « dissimulée ». J’y reviendrai.
III. Le Web sémantique : comme un apport à une « intelligence artificielle » ?▲
Cela peut surprendre – et je l’ai été le premier lorsque j’ai commencé mes recherches sur ce domaine –, mais le Web sémantique de 1994 est lié (négativement) par Tim Berners-Lee lui-même à l’intelligence artificielle. Plus exactement à la branche qui existait alors et qui fonctionnait plus ou moins bien. Pourquoi avoir explicitement indiqué dans le document de travail présentant le projet du Web sémantique, une telle référence ? Revenons un instant à l’histoire afin de poser le contexte.
Tim Berners-Lee fonde en 1994 le W3C, la représentation permanente d’une Conférence appelée WWW du MIT. Pour aider les utilisateurs humains du Web, il introduit non pas l’idée d’un ordinateur intelligent – à cette époque, l’IA est à la fin de son second « hiver » et les performances, médiocres, patinent – mais plutôt l’idée d’un réseau « intelligent » car celui-ci serait conçu pour être naturellement pertinent (en plus d’être complet, c.-à-d. universel) et les « agents » (les machines qui le composent) seraient capables de retrouver et manipuler, seuls, les données dont ils ont besoin.
En 1998, un premier jalon important est produit par le W3C sous la signature de Tim Berners-Lee : la Semantic Web Road Map ou en bon français, la feuille de route du Web sémantique. Le RDF en sera ici moins une sorte de conclusion qu’une étape.
|
« The Web was designed as an information space, with the goal that it should be useful not only for human-human communication, but also that machines would be able to participate and help. One of the major obstacles to this has been the fact that most information on the Web is designed for human consumption, and even if it was derived from a database with well defined meanings (in at least some terms) for its columns, that the structure of the data is not evident to a robot browsing the web. Leaving aside the artificial intelligence problem of training machines to behave like people, the Semantic Web approach instead develops languages for expressing information in a machine processable form. |
Le Web a été conçu comme un espace d’information, dans le but d’être utile non seulement pour la communication humaine, mais également pour que les machines puissent participer et aider. L’un des principaux obstacles à cette situation est le fait que la plupart des informations sur le Web sont conçues pour la consommation humaine et même si elles proviennent d’une base de données avec des significations bien définies (au moins en certains termes) pour ses colonnes, la structure des données n’est pas évidente pour un robot naviguant sur le Web. Laissant de côté le problème de l'intelligence artificielle des machines d'entraînement pour se comporter comme des personnes, l'approche du Web sémantique développe plutôt des langages permettant d'exprimer des informations sous une forme pouvant être traitée par une machine. |
C’est une première déclaration fort intéressante. Dans un autre document que je citerai plus loin, il indique clairement que l’objectif n’est pas de s’adresser à des machines qui peuvent s’entraîner seules (tout à fait théoriques à cette époque) :
|
« A Semantic Web is not Artificial Intelligence. |
Un Web sémantique n'est pas une intelligence artificielle. |
En faisant un peu d’histoire des sciences, le projet du Web sémantique s’apparente donc à la création d’une immense base d’informations qui pourrait servir à des systèmes « experts » qui, eux, à cette époque, sont jugés alors très performants (ça ne durera pas).
De ces informations rassemblées, facilement accessibles et correctement indexées, de tels systèmes peuvent alors produire des inférences (des déductions logiques) :
|
« The Semantic Web is a web of data, in some ways like a global database. The rationale for creating such an infrastructure is given elsewhere [Web future talks &c] here I only outline the architecture as I see it. » |
Le Web sémantique est un réseau de données, à certains égards semblable à une base de données mondiale. La justification de la création d'une telle infrastructure est indiquée ailleurs [conférences sur le futur Web et autres], je ne décris ici que l'architecture telle que je la vois. |
En aparté, ce changement de paradigme n’est pas sans conséquence sur « l’esprit » du Web – il parle lui-même de la nécessité de justifier de ce changement – et intervient alors que peu de temps auparavant, l’industrie informatique est entrée en émoi : les machines de bureau deviennent courantes, plus performantes que les modèles existants, tout particulièrement les systèmes industriels basés sur des architectures matérielles très différentes. Les machines LISP notamment, dont la programmation symbolique (lambda-calcul, 1958) a été à l’origine d’innombrables langages de programmation ensuite, feront les frais de cette évolution matérielle et disparaîtront, bien qu’elles auraient été, à bien des égards, parfaitement adaptées à la « logique » de RDF.
Revenons au sujet initial. Ne vous méprenez pas sur mon propos : le Web sémantique n’est pas lié au sujet d’une intelligence artificielle. L’idée n’est pas de permettre l’émergence d’une IA – surtout une IA unique ou unifiée –, mais plutôt le « raisonnement automatique » lié à ces agents que sont les navigateurs et les machines qui composent le réseau. Ce raisonnement automatique s’appuie dans son approche sur le fonctionnement des systèmes experts. Cette distinction doit être bien comprise pour la suite de l’article.
IV. Focus sur le système expert▲
Arrêtons-nous un instant sur ce qu’est un système expert : il a été l’une des branches majeures de l’intelligence artificielle, car, d’après la définition pédagogique de Wikipédia, « un système expert est un outil capable de reproduire les mécanismes cognitifs d'un expert, dans un domaine particulier. Il s'agit de l'une des voies tentant d'aboutir à l'intelligence artificielle. Plus précisément, un système expert est un logiciel capable de répondre à des questions, en effectuant un raisonnement à partir de faits et de règles connues. Il peut servir notamment comme outil d'aide à la décision ».
L’autre particularité, qui ne nous concerne pas directement dans cet article, mais le sépare profondément de l’IA telle qu’elle est envisagée de nos jours, est la capacité d’un système expert à être audité (humainement), c’est-à-dire de donner les éléments qui lui ont permis d’aboutir à un résultat et de pouvoir ainsi vérifier la validité du résultat. Ce fonctionnement est permis par un procédé sous-jacent itératif (ce qui n’empêche pas l’amélioration des performances en privilégiant certaines opérations).
LISP (branche Emacs ou d’autres ; devenu plus tard Common LISP), ou PROLOG, sont particulièrement adaptés à de tels systèmes, tout comme la programmation symbolique et fonctionnelle dans son ensemble.
Tout le système repose sur une base de faits et une base de règles (c.-à-d.. comme des bases de données spécialisées) et d’un moteur d’inférence, c’est-à-dire qu’il « déduit » logiquement des données qu’il a, d’autres données (en l’occurrence, d’autres règles ou d’autres faits).
Voici quelques exemples à partir des éléments suivants :
- faits : j’ai 3 pommes ; j’ai 3 œufs ; j’ai 0,5 litre de lait ; j’ai de l’eau sans limites
- règle : tarte aux pommes = 3 pommes + 2 œufs + 1 kg de farine
- règle : flan aux pommes = 4 pommes + 3 œufs + 0,1 litre de lait
- règle : crêpes saveur pomme = 3 jus de pommes + 1 litre de lait + 5 œufs
- règle : compote de pommes = 2 pommes
- règle : le lait se délaye avec de l’eau (un pour deux)
- règle : le jus de pomme se fait en extrayant le jus des pommes (1 jus = 1 pomme)
- règle : le jus de pomme est composé d’eau
Nous pouvons déduire logiquement (logique booléenne – c.-à-d. « vrai ou faux ») :
- fait : je ne peux pas faire de tarte aux pommes
- fait : je ne peux pas faire de flan aux pommes
- fait : je ne peux pas faire de crêpes saveur pomme
- fait : je peux faire de la compote de pommes
- fait : je peux délayer jusqu’à l’équivalent d’un litre de lait
- règle : en extrayant le jus de pommes, il reste de la « matière pomme »
Nous pouvons déduire logiquement (logique floue – c.-à-d. « plus ou moins vrai ») :
- fait : je ne peux que difficilement réaliser la tarte aux pommes (= manque de farine)
- fait : je peux assez facilement réaliser le flan aux pommes (= réduire la quantité de pommes)
- fait : je peux assez facilement réaliser les crêpes aux pommes (= ajuster la quantité de pâte au nombre d’œufs disponibles)
- fait : je peux certainement réaliser de la compote de pommes
- règle : je peux certainement ajouter de l’eau à la matière pomme pour reformer des pommes (certes, c’est théorique… NDR)
- fait : je peux certainement réaliser de la compote de pommes après les crêpes aux pommes (= ajouter de l’eau à la matière pomme pour reformer des pommes)
Comme pour tout ce qui concerne l’IA dans son ensemble, il peut y avoir un manque de cohérence (aller « trop loin » dans le raisonnement, aboutir à des incohérences) ou une absence de validité des éléments fournis au système (la déduction sera biaisée).
Le système expert peut se retrouver dans tous les domaines où la recherche d’une solution se fait dans un cadre formel (comptabilité, santé, industrie, etc. ; voir des exemples sur le site de SupInfo). Il aide ou remplace un « expert », un spécialiste humain. Il sera profondément inadapté à des systèmes dits « naturels » où peu ou trop de règles s’appliquent, sont impossibles à expliciter ou si celles-ci évoluent trop vite.
Or, comme nous le verrons plus loin, connaissances, organisation humaine et systèmes experts se marient plutôt bien. C’est très probablement dans cet état d’esprit que Tim Berners-Lee a appréhendé le Web sémantique et RDF.
V. Relation entre Web sémantique et RDF▲
Jusqu’à présent, j’ai lié le Web sémantique à RDF, car le concepteur était le même. Il reste à valider cette liaison de manière plus formelle. Les textes de l’époque introduisent à la fois le besoin et l’amorce de la solution et argumentent cette liaison.
|
« When looking at a possible formulation of a universal Web of semantic assertions, the principle of minimalist design requires that it be based on a common model of great generality. Only when the common model is general can any prospective application be mapped onto the model. The general model is the Resource Description Framework. (…) |
Lorsqu'on examine une possible formulation d'un réseau universel d'assertions sémantiques, le principe de la conception minimaliste exige qu'elle repose sur un modèle commun d'une grande généralité. Ce n'est que lorsque le modèle commun est général, que toute application prospective peut être mappée [appliquée] sur le modèle. Le modèle général est celui d’un cadre de description de ressource. (…) |
De cet extrait, nous pouvons garder trois idées maîtresses.
Premièrement, la relation entre Web sémantique et RDF est aisée : le Web « classique » rend le Web sémantique nécessaire et RDF rend possible le concept du Web sémantique. En cela, RDF n’est pas (seulement) un « langage de représentation des données », vous pouvez d’ailleurs « faire du RDF » avec des syntaxes très différentes : JSON, XML, (x)HTML ou Turtle (Terse RDF Triple Language)… ou l’équivalent du CSV comme dans les deux premières parties de cette série.
Deuxièmement, cet extrait indique qu’une information dépend aussi de présupposés, que l’on pourrait considérer comme un « contexte » ou l’environnement sémantique. Si par exemple, je vous dis simplement « Napoléon aime le chocolat », vous aurez une représentation de cette information comme un ancien empereur français qui avait une fâcheuse tendance à la gloutonnerie et pas à mon chat qui apprécie particulièrement faire ses griffes sur le délicat papier peint marron du salon… Appliquez n’importe quelle logique sur un élément de départ dont votre perception est différente de la mienne et vous aurez un résultat… logique, mais inattendu (et erroné pour le commanditaire).
La troisième et dernière idée majeure de cet extrait est la vue d’ensemble de RDF : son intérêt n’a de sens que pour faire travailler et échanger des systèmes hétérogènes (ce qui peut être compris des « applications ») ; le Web est un exemple parfait !
Ainsi, RDF est à la fois (1) la validation technique d’un concept de gestion documentaire des informations et donc des connaissances ; (2) l’entremise par laquelle vous pourrez réaliser des raisonnements cognitifs (logique combinatoire, floue, etc.) en fonction du contexte, des données précédentes et de la demande au travers d’un certain nombre d’acteurs (dont vous-même) ; (3) un protocole technique permettant de représenter une donnée ou un lien dans un ensemble, sans nécessairement connaître cet ensemble de manière exhaustive et sans que ce dernier ait besoin d’être homogène dans sa représentation conceptuelle (à l’exception de son support).
RDF est à l’origine dédié à une exploitation via un réseau étendu, Internet particulièrement. Mais rien n’empêche son utilisation sur un réseau local ou même sur sa seule machine. Cet universalisme contribue, à mon sens, à perdre parfois de vue ses nombreux apports dans l’informatique courante.
Un peu avant la publication de cette feuille de route, Tim Berners-Lee a publié un article sur ce que n’est pas le Web sémantique et in fine le RDF qui en est issu. Ce génial inventeur rappelle que c’est bien une approche « ouverte » qui fonde sa pensée et donc son modèle et que cette approche est la plus pertinente (il a eu raison) :
|
« Where the other models are related to previous unmet promises of computer science, now passed into folk law as unsolvable problems, they suggest a fear that the goal of a Semantic Web is inappropriate. |
Là où les autres modèles sont liés à des promesses précédentes non remplies de la science informatique, désormais transposées dans la culture populaire en tant que problèmes insolubles, ils suggèrent une crainte que l'objectif du Web sémantique soit inapproprié. |
En somme, l’utilisation de RDF pour la définition du Web sémantique permet une approche en quelque sorte « relativiste » de la connaissance, limitée à un domaine d’activité ou à un nombre d’acteurs. Il ne s’agit pas de produire ou de répondre à une question par une réponse universelle ou parfaite, mais de répondre avec les données qui sont actuellement disponibles (ou traitables dans un temps « raisonnable ») avec un angle, une approche précise, comme le ferait l’humain avec sa subjectivité.
RDF a une seconde propriété remarquable : il est très graphique (ce qui, je vous l’accorde volontiers, ne saute pas aux yeux naturellement). Cela, grâce à l’un des prérequis de former le Web sémantique grâce à des graphes, hérités des liens (relations) hypertextuels dans les documents (entités). Un graphe RDF, représenté pour l’homme, ressemble à quelque chose comme ceci :
Format textuel, nous y reviendrons plus tard :
<Bob> <is a> <person>.
<Bob> <is a friend of> <Alice>.
<Bob> <is born on> <the 4th of July 1990>.
<Bob> <is interested in> <the Mona Lisa>.
<the Mona Lisa> <was created by> <Leonardo da Vinci>.
<the video 'La Joconde à Washington'> <is about> <the Mona Lisa>Format graphique :
|
|
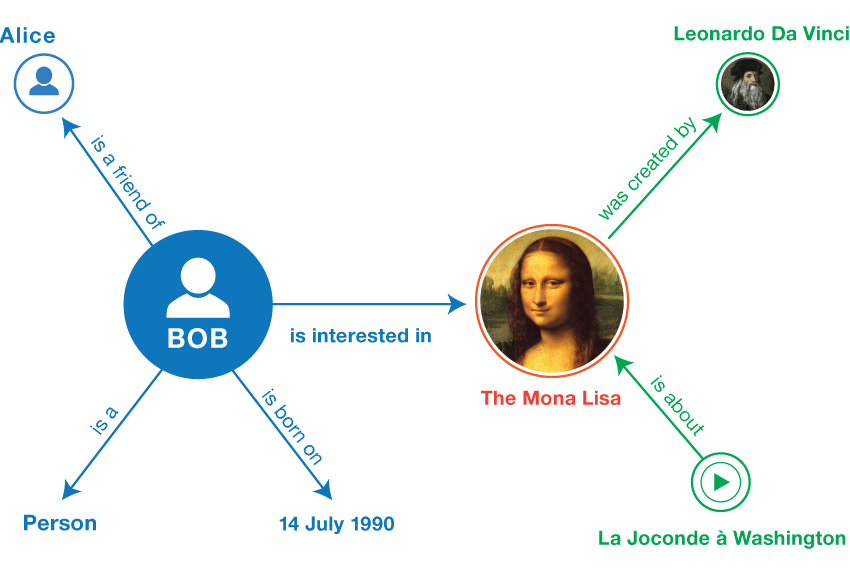
Nous comprenons donc que cela crée en quelque sorte des « objets » – les entités – qui disposent de propriétés (les relations d’un graphe pouvant être des objets eux-mêmes).
Pour autant, Tim Berners-Lee ne place pas un signe d’égalité entre « objet » et RDF. Un objet (fut-il représenté dans un graphe) est une représentation de données RDF, mais RDF s’en émancipe. La raison en est simple : RDF fonctionne à travers un réseau qui n’a pas besoin et n’a pas la possibilité d’être parcouru intégralement. Dit autrement, c’est comme si les membres de votre objet, ses propriétés, n’étaient pas nécessairement liées à lui. Reprenons son propos :
|
« The Semantic Web and Entity-Relationship models. |
Le Web sémantique et les modèles d'entité-relation. |
Il ne s’agit donc pas de dériver un objet d’une classe ou d’un objet parent, mais d’ajouter une entité (un triplet) dont la définition est ailleurs (et cette définition même est une entité qui est définie par une autre entité, etc.). RDF se passe donc d’une origine « absolue » – même si nous pouvons parfaitement en définir une. L’ontologie, que j’évoquerais plus loin, pourrait répondre à une telle définition d’un « point zéro ».
L’intérêt, vous l’aurez compris, est de détacher la définition d’une information de l’information elle-même. RDF définit en cela le fonctionnement du Web sémantique et donc plus largement de ce qu’est un système sémantique automatisable.
Dans l’approche, le Web sémantique n’est par contre absolument pas une opposition à une base relationnelle (type SQL par exemple). RDF peut contribuer au contraire à interconnecter des bases relationnelles, en modélisant des ressources nouvelles à partir des données sérialisées dans une base relationnelle. Tim Berners-Lee évoque d’ailleurs qu’il s’est inspiré des enregistrements de telles bases pour définir RDF.
|
« The Semantic Web and Relational Databases. |
Le Web sémantique et les bases de données relationnelles. |
Enfin, toujours dans cet article, Tim Berners-Lee indique « RDF is not an Inference system » (RDF n’est pas un système d’inférence). Cela pourrait sembler contradictoire avec les autres propos (raisonnement automatique et mes propres écrits sur les systèmes experts). C’est pourtant assez logique : RDF ne prévoit pas un moteur ou une procédure particulière. RDF permet à un système, expert, d’IA ou simplement un navigateur qui extrait des données d’un document sans autre opération, de se repérer et d’aller chercher une définition ou une ressource ailleurs.
Sortons du Web sémantique et concluons notre sujet : ce qu’est finalement RDF, Resource Description Framework et ce qu’il apporte au quotidien dans une organisation humaine.
VI. RDF : des triplets, pas de document et un peu l’évolution du XML▲
|
|
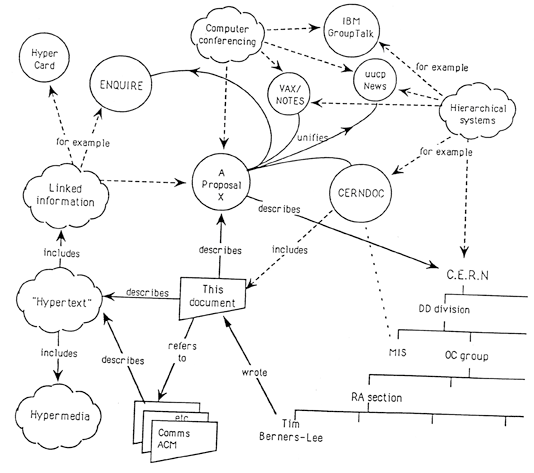
Le Web, en 1989, par le patron de Tim Berners-Lee : « Vague, but exciting ! » Si vous comprenez ce schéma : félicitations, vous avez parfaitement compris le système de références propre à RDF. Reste à formaliser tout ça…
J’ai un peu omis quelques parties sur RDF jusqu’à présent, notamment le poids de XML auprès de RDF. Sur le Web sémantique, XML pèche pour régner en maître seul. Car XML formalise un arbre au sein d’un document fini. Entre deux documents, chaque arbre peut être différent des autres et la jonction entre ces deux documents est complexe, voire impossible. Bien que XML soit « autodocumenté » bien davantage que JSON par exemple (le nom des balises peut avoir un sens pour la machine, comme pour HTML), cela reste limité à l’usage qu’en a pensé le concepteur. XML n’a du sens que « dans un système fermé » comme l’indiquait Tim Berners-Lee plus haut. Ce n’est pas sa conception qui est un problème, mais la manière dont il est utilisé : difficile de se mettre d’accord pour un balisage universel au risque de perdre ce qui fait sa force.
RDF a en quelque sorte « contourné » cette difficulté. Vous pouvez très bien utiliser XML comme syntaxe pour RDF. Votre document est alors figé d’un point de vue syntaxique, mais tout à fait libre d’un point de vue sémantique. Comparer et/ou regrouper deux, trois, dix ou des millions de documents RDF-XML n’est pas une difficulté, même à l’époque.
HTML est pour le Web, comme XML pour les données, un format standard, mais sur lequel l’universalisme du sens de chaque élément est encore un rêve assez éloigné (partageons quelques instants la douleur des développeurs Web…).
Alors pourquoi RDF y arrive-t-il, là où d’autres échouent et accessoirement ceux qui échouent semblent bien davantage utilisés ou appris dans les centres de formation ? Simplement : vous faites du RDF sans le savoir.
Le RSS ou Atom de votre site préféré Developpez.com ? Du RDF.
Un ODT (qui n’est qu’un ZIP enfermant du XML) ? (En partie) du RDF.
ActivityPub (que j’ai traité ici), qui est la nouvelle norme du W3C pour la décentralisation du Web social ? Du RDF.
Oauth ? Repose sur les notions développées par RDF.
L’ensemble des données de l’INSEE disponible via une API normalisée afin d’être utilisé dans tout l’univers connu ? Du RDF.
Si vous deviez concevoir un outil d’open-data pour votre entreprise (de manière rémunérée ou non) ? Du RDF.
Et d’autres exemples, nombreux, peuvent être trouvés (Qwant est votre ami). Si RDF est (relativement) peu appris ou énoncé, c’est qu’il n’est pas nécessaire de connaître toute la théorie pour l’utiliser : c’est sa force. Plutôt qu’arrêter une syntaxe, il définit une idée tellement pertinente et adaptable qu’il est facile d’oublier qu’on en fait…
Comme je l’indiquais en introduction de la première partie de cette série d’articles, RDF se résume à l’utilisation de triplets (aucun, un ou plusieurs en retour des requêtes SPARQL). Pour faire simple, imaginez une phrase : la construction est la même… « Paul a un polo rouge » :
- « Paul » est le sujet ;
- « a » (= la possession à un instant ou en général) est un prédicat (au sens de jointure) ;
- « un polo rouge » est l’objet.
Imaginez que l’on ait défini Paul sur Internet grâce à son site « paul.com ». La possession serait exprimée au travers d’un lien vers la définition dans le dictionnaire « dictionnaire.fr/def/possession » et « un polo rouge » renvoie vers un site marchand « couture.org/polo#rouge ». Vous avez alors un triplet parfaitement conforme :
Sujet ( Paul ) Prédicat ( a ) Objet ( un polo rouge )
==
Sujet ( paul.com ) Prédicat ( dictionnaire.fr/def/possession )
Objet ( couture.org/polo#rouge )…Votre système reçoit ce triplet. Il ne connaît rien au goût de cet inconnu. Mais il va pouvoir, grâce aux liens, récupérer les informations et reconstruire la connaissance « Paul a un polo rouge ». Mieux : si vous posez la question : « est-ce que Marie a une veste bleue ? », il pourra consulter les amis de Paul, en définissant ce qu’est « un ami » au travers d’autres triplets ; savoir si « Marie » existe dans les « amis » de « Paul » et si éventuellement, « Marie » « a » « une veste bleue ».
La machine ne comprend absolument pas « Marie », « veste bleue » ou « dimanche ensoleillé » – ce n’est pas le sujet de faire d’elle une intelligence artificielle. Par contre, elle est capable d’avoir des raisonnements cognitifs sur les données des triplets (système expert) ou retrouver toutes les personnes nées un premier janvier sur les sites qui regroupent des membres inscrits et dont l’API consultable est compatible RDF (agent simple).
L’enjeu du Web sémantique n’est donc pas que la machine comprenne le sens, mais qu’elle appréhende des symboles et fonctionne et aide l’utilisateur humain, avec ces mêmes symboles. RDF s’appuie de plus sur l’architecture du réseau Internet (HTTP, URL/URI) pour récupérer les données. Le triplet que je prenais en exemple peut avoir un identifiant unique sur un site, par exemple « connaissances.eu/triplet#1 ». La référence de ce triplet sera globale, car Internet est global. La résolution du nom de domaine, unique dans le monde, permet d’assurer à la fois l’unicité du site porteur du triplet, mais aussi une grande diversité de sens natifs possibles (c.-à-d. la spécialisation d’un site).
La connaissance « Paul a un polo rouge » depuis mon triplet peut être reconstruite à n’importe quel endroit de la terre et, virtuellement, dans toutes les langues du monde. En outre, l’utilisation des technologies de sécurité propres au Web, comme TLS, permet une récupération sécurisée : vous avez donc avec une autorité « de confiance » (certification), la possibilité de sécuriser votre connaissance en sécurisant les sources qui la composent.
Mieux : même si votre triplet reste fixe, vous pouvez récupérer des données différentes, mises à jour : « Marie » peut ne pas exister aujourd’hui et exister demain… L’inverse est aussi vrai : le polo peut exister aujourd’hui (la ressource est disponible) mais ne pas exister demain. Qu’importe : le lien, même invalide, reste en soi porteur de sens.
Le réseau donc, apporte par des millions d’éléments, de triplets, une « vue » globale des connaissances. Suivant votre capacité et votre temps disponible à interroger des services fournissant des informations compatibles avec RDF, vous aurez une information plus ou moins précise, complète et redondante (la redondance peut être ici vue comme facteur de consensus…).
Cependant, de nombreux défauts peuvent apparaître : sur l’exemple de tout à l’heure, comment définir par exemple, ce qu’est un « ami » ? Des liens d’amitié noués dans le temps ou de simples déclarations, souvent purement performatives, comme sur un tristement célèbre réseau social dont le logo est un ‘F’ ?
Bref, sans une « origine » ou une définition commune (cf. monde « ouvert »), en balayant forcément moins de sources qu’un humain et sans réelle intelligence artificielle qui comprenne de la même façon que l’humain, RDF connaît une limite. Ce qui fait sa force et sa faiblesse : le sens, c’est aussi une question de consensus dans un groupe donné.
Comment créer ce consensus, comment l’organiser, afin de ne pas retomber dans les travers soit d’un système fermé, soit d’un système tellement hétérogène qu’il se balkanise ?
VII. RDF(S), ontologie et métiers : Linked Enterprise Data▲
Vous imaginez bien que nous n’avons pour l’instant abordé que l’écume de concepts bien plus profonds. Je vous épargne ici les bases mathématiques, sociologiques ou linguistiques de cet ensemble si vaste. D’excellents cours, sur l’INRIA notamment, évoquent avec bien plus de brio ces aspects. Je vous recommande d’ailleurs de ne considérer cet article que comme une simple introduction !
Dans la partie précédente, j’ai essayé de réduire RDF à une question : une fois l’organisation comprise (triplets ; référencement à l’échelle du Web ; gestion du sens à travers des symboles par la machine), comment se mettre d’accord sur l’organisation même des connaissances ?
Jusqu’à présent, dans les deux premiers articles de cette série, j’ai évoqué des aspects purement techniques (des données). Les parties précédentes de ce troisième article évoluent et parlent d’informations. Cependant, RDF gère aussi et principalement des connaissances qui doivent être :
- hiérarchisées (ex. l’une sous l’autre) ;
- comparées (ex. l’une vs l’autre) ;
- historisées (ex. l’une après l’autre) ;
- mises en relation de manière ordonnée entre elles (ex. l’une avec l’autre).
En quelque sorte, ce que j’ai appelé jusqu’à présent « contexte » est en réalité l’ensemble des connaissances autres que celles que vous avez en tête et qui pourtant la définissent. Exemple : le polo rouge de Paul n’a de sens que si vous connaissez effectivement une personne qui s’appelle Paul ou que vous reconnaissez Paul comme quelque chose de possible, qui puisse être appréhendé.
Or, Paul est ici supposé être un humain, mais pourquoi ? Ce pourrait être aussi un chien (oui, les chiens peuvent porter des polos), un fantôme (plus rare) ou une table basse (très rare). Si Paul a toutes les chances d’être humain, c’est parce que j’ai indiqué implicitement, dans la ressource sur le polo, que ce même polo était un vêtement pour les humains. Cela implique donc qu’il existe des vêtements pour d’autres entités que des humains… sauf si explicitement vous indiquez que non, un vêtement est seulement pour l’humain.
La réponse à cette problématique s’appelle l’ontologie : définir des règles sur l’organisation de la connaissance humaine pour que la machine accepte correctement le sens d’une donnée.
Voici ce qu’en dit Wikipédia:
« En informatique et en science de l'information, une ontologie est l'ensemble structuré des termes et concepts représentant le sens d’un champ d'informations, que ce soit par les métadonnées d'un espace de noms ou les éléments d'un domaine de connaissances. L'ontologie constitue en soi un modèle de données représentatif d'un ensemble de concepts dans un domaine, ainsi que des relations entre ces concepts. Elle est employée pour raisonner à propos des objets du domaine concerné. Plus simplement, on peut aussi dire que l’« ontologie est aux données ce que la grammaire est au langage ». (…)
L'objectif premier d'une ontologie est de modéliser un ensemble de connaissances dans un domaine donné, qui peut être réel ou imaginaire.
Les ontologies sont employées dans l’intelligence artificielle, le Web sémantique, le génie logiciel, l'informatique biomédicale ou encore l'architecture de l'information, comme une forme de représentation de la connaissance au sujet d'un monde ou d'une certaine partie de ce monde. Les ontologies décrivent généralement :
- individus : les objets de base ;
- classes : ensembles, collections ou types d'objets ;
- attributs : propriétés, fonctionnalités, caractéristiques ou paramètres que les objets peuvent posséder et partager ;
- relations : les liens que les objets peuvent avoir entre eux ;
- événements : changements subis par des attributs ou des relations ;
- métaclasses (Web sémantique) : des collections de classes qui partagent certaines caractéristiques. »
L’ontologie en informatique est donc prioritaire au-delà de RDF qui est un outil. C’est en quelque sorte la possibilité de trier et mettre en relation des objets, ces objets pouvant être des entités qui évoluent indépendamment les unes des autres.
Le corollaire, c’est qu’un « document » pour RDF est plus un instantané qu’autre chose : vous faites votre requête, votre recherche, au moyen de votre agent sur n sources. Le résultat est un document, mais qui n’est valable qu’un moment. Le principe de RDF serait presque de n’avoir aucun document, d’aucune forme – hormis ce qui est à destination humaine – mais simplement des entités les plus petites possibles que l’on récupère, que l’on infère (c’est-à-dire que l’on déduit) et que l’on organise.
Revenons à notre exemple : pour la machine, cela infère que Paul est humain parce qu’il a en sa possession un vêtement fait pour les humains. Mais est-ce qu’un vêtement est la même famille / classe qu’un humain ? Non : le vêtement est un objet et Paul est vivant (un animal). Pour que la machine le comprenne, elle devra résoudre elle-même ce point (elle le peut).
L’ontologie arrive pour déterminer les relations, la hiérarchie et la validité des concepts entre eux ; ce qui est un métier en soi. Pour une organisation comme une entreprise par exemple, l’ontologie serait d’avoir un descriptif de toute l’activité, même la plus marginale, qui existe numériquement ou non, bien au-delà d’une notion de métiers. Cette description permet à une machine seule ou un groupement de machines de traiter des données formalisées et appréhendées par l’humain, afin d’en tirer une interface graphique, un processus logique, une action sur une machine ou l’organisation du stock avec des ordres chez les fournisseurs…
Le plus intéressant, c’est que RDF étant décrit comme systématique à l’échelle du Web, en prenant des ontologies qui font consensus (comme Foaf – friend for a friend pour les relations humaines par exemple ou Dublin Core pour la gestion documentaire), vous pouvez naturellement échanger les informations avec vos clients, prestataires ou n’importe qui, sans transformation particulière : un triplet, référencé à l’échelle du Web et sur une ontologie (re)connue, est le gage absolu de la bonne réception d’une connaissance.
Ainsi, pourquoi créer un document, forcément figé, fini, lorsque vous pouvez n’envoyer qu’une référence, un lien, vers une ressource qui sera mise à jour au besoin ?
Imaginez par exemple que vous vendiez des biens partout en France grâce à des livreurs en camion. Votre SIG – système d’information géographique – est un impératif, notamment pour les codes postaux ; votre suivi logistique aussi. Or, en France, les communes fusionnent (parfois les Régions aussi). Des « communautés de communes » – un nouveau concept – se créent. RDF résout ce problème de maintenance du sens et de la donnée géographique.
L’idéal étant que votre SIG s’interface parfaitement avec vos outils de suivi logistique : les données de l’INSEE, dont l’API est publique et « au format RDF », vous permettent d’avoir en temps réel l’information la plus à jour pour SIG, et comme votre outil de suivi logistique les comprend, l’ensemble est maintenu automatiquement, naturellement et en temps réel face aux changements institutionnels.
Une ontologie métier, interne à votre structure, permet à chaque outil qui prend en charge RDF, de recevoir et livrer de l’information avec de puissants outils d’aide à la décision, sans provoquer la lourdeur, le coût ou les risques que connaissent les outils liés à l’apprentissage d’une IA (du moins pour l’instant).
Mieux : vous pouvez imaginer que pour chacun de vos entrepôts, partout en France, en fonction de leurs besoins individuels, la gestion des distances, des coûts de transports, etc. soient intégralement confiés à la machine en liant les données.
Ce domaine s’appelle Linked Enterprise Data – les données d’entreprises liées (ou en bon français, la liaison des données professionnelles). Une bonne ontologie, suffisamment ouverte sur le monde et précise sur l’activité d’une entreprise, permet de grandes réalisations et, a minima, de décrire des processus qui souvent échappent aux définitions et appréhensions traditionnelles des Systèmes d’Information.
Alors finalement, en conclusion, l’ontologie qu’est-ce que c’est factuellement ? Du RDF : une ontologie est décrite comme le serait un document issu d’un traitement via RDF. La représentation est donc la même : sous la forme d’un graphe orienté. L’ontologie se retrouve donc dans les graphes des connaissances (ici avec FOAF) :
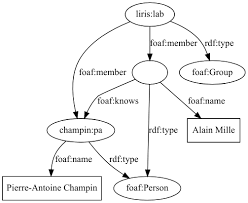 |
RDF devient alors RDF-S (pour Schéma ; RDF étant pour les ressources). RDF-S est publié par le W3C comme une norme, bien que son origine remonte pratiquement à la naissance de RDF : cela facilite l’acceptation et la mise en œuvre de ce qui est un brillant outil, mais peut-être intellectualisant à outrance, pour une vision strictement productive…
RDF-S introduit la notion de classes et de sous-classes ; des propriétés liées à un domaine ; des types ou encore des collections (une liste ordonnée d’éléments)… Ci-dessous, nous voyons un exemple sur le classement du règne animal :
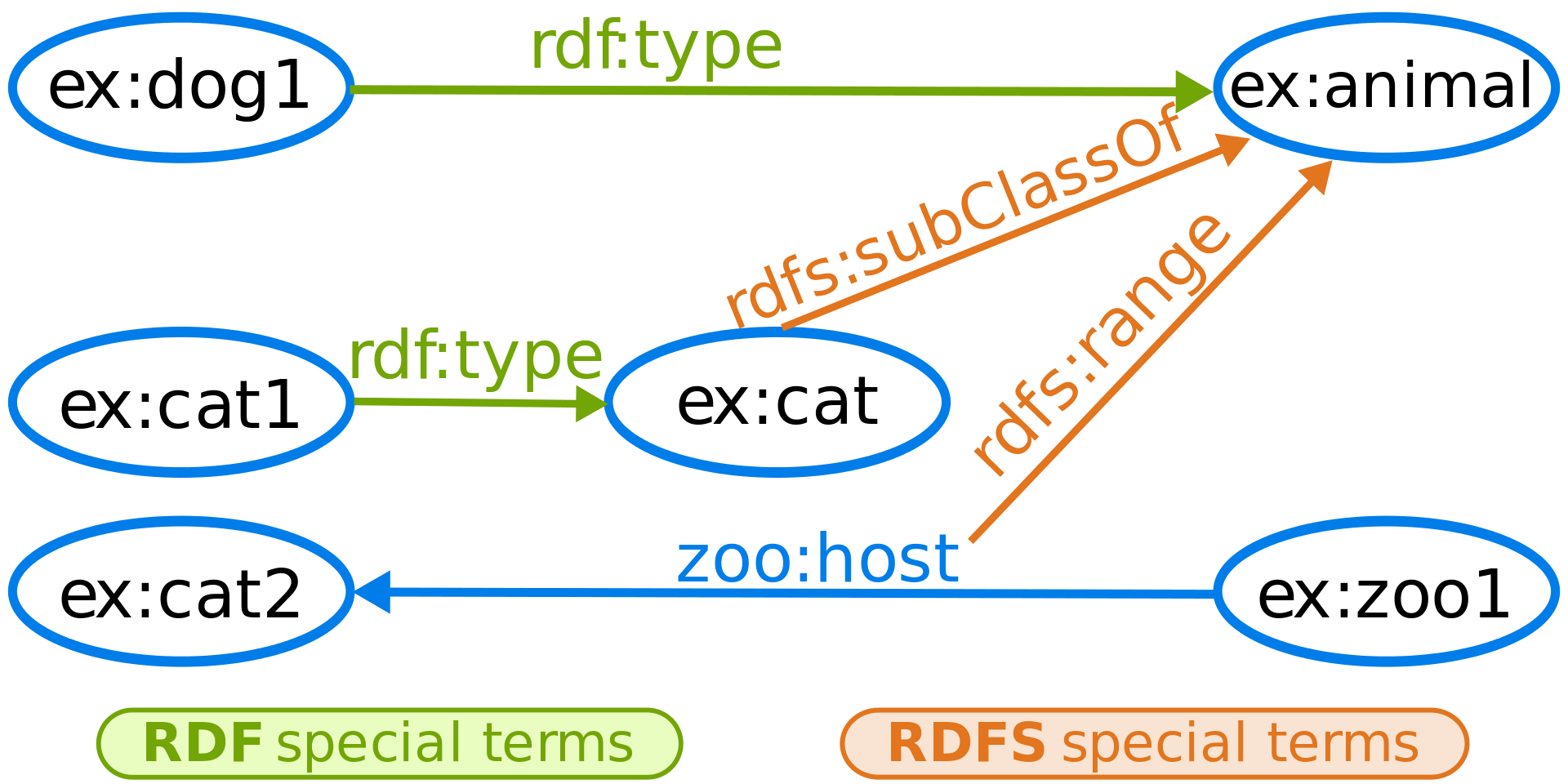 |
Si l’on reprend l’affaire du polo rouge, notre ami Paul serait cousin de ex:cat1 (« ex » signifiant « exemplaire ») avec l’identifiant ex:Paul1.
Ex:Paul1 aurait un prédicat (une relation de type rdf:type) avec l’objet ex:humain. Cet objet étant lui-même sujet et sous-classe (rdfs:subClassOf) de ex:animal.
Si Paul est « disjoint » des chats (Paul n’est pas un chat et s’il en est un, il ne peut pas être un humain), les chats et Paul sont joints du fait d’être tous les deux des animaux. Paul et les chats sont par ailleurs disjoints des vêtements, car les vêtements ne sont pas des humains ni des animaux, ni même vivants. Possiblement, Paul, les chats et les vêtements peuvent tout de même être joints… s’ils sont tous sur le territoire français.
Tout n’est qu’affaire de questions et de perception !
VIII. Postambule▲
Cette série d’articles sur les connaissances s’arrête. J’espère vous avoir apporté tous les termes et concepts-clefs afin de mieux comprendre RDF, la gestion de la sémantique et donc de la connaissance, loin des voies habituelles. J’espère surtout vous avoir donné l’envie de tester et d’en découvrir davantage.
Merci pour votre lecture et à très bientôt sur les forums de Développez.com !
IX. Note de la rédaction de Developpez.com▲
Nous tenons à remercier escartefigue pour la relecture orthographique de ce tutoriel.