



I. Introduction▲
I-A. Mises en garde▲
Cet article aborde le sujet dâextensions à votre navigateur avec des concepts poussÃĐs et de nombreux chausses-trappes mÊme pour un dÃĐveloppeur JS expÃĐrimentÃĐ. Cela nâindique pas que ce tutoriel leur est rÃĐservÃĐ, mais un certain niveau de connaissances est recommandÃĐ pour saisir pleinement les imbrications et comprendre que certaines ÂŦ limitations Âŧ que jâexpose, sont en rÃĐalitÃĐ des nÃĐcessitÃĐs absolues.
Du fait de la plus grande libertÃĐ dans lâaccÃĻs aux donnÃĐes et des ÂŦ droits Âŧ accordÃĐs, ces extensions agissent bien au-delà de leur prÃĐ carrÃĐ et peuvent intercepter, modifier et annuler à la fois des requÊtes (de maniÃĻre transparente pour lâutilisateur, pour les entÊtes ou les corps de requÊtes) mais aussi certains protocoles de sÃĐcuritÃĐ (en les contournant voire en les supprimant : par exemple la rÃĐcupÃĐration dâun corps de requÊte sur une liaison TLS ou dâannuler une requÊte en HTTPS au profit de HTTP seulement). Câest-à -dire rendre vulnÃĐrable votre navigateur à des attaques ou à des exploits.
Câest aussi permettre de faire des captures dâÃĐcran, de stocker et tÃĐlÃĐcharger des fichiers sur le poste du client, crÃĐer des PDF à la demande, gÃĐrer les onglets, lâhistorique, les marque-pages et tant dâautres chosesâĶ
Pour cela, je vous indique ici trois rÃĻgles dâor qui peuvent paraÃŪtre extrÊmes mais comme nous le verrons plus loin, sont à la mesure de ce qui est offert par les API que nous utiliserons.
- Ne testez pas votre WebExtension sur votre navigateur ÂŦ quotidien Âŧ. Tester dans une installation de votre navigateur ÂŦ autonome Âŧ et dans un environnement si possible limitÃĐ (chroot). Seulement lorsque vous serez sÃŧr, testez en conditions plus ÂŦ rÃĐelles Âŧ.
- Nâaccordez pas de droits ÂŦ inutiles Âŧ à votre WebExtension, particuliÃĻrement WebRequest et WebNavigation. Ne tenter pas de communiquer avec des domaines ou des serveurs que vous ne connaissez pas et ne laissez jamais un serveur distant, mÊme lÃĐgitime, ÂŦ prendre le contrÃīle Âŧ de votre WebExtension.
- Gardez à lâesprit que votre WebExtension, par sa seule prÃĐsence, doit Être considÃĐrÃĐe comme dÃĐgradant les performances et la sÃĐcuritÃĐ â mÊme si elle offre un service lÃĐgitime : elle vient toujours en modifiant le processus normal et optimisÃĐ de votre navigateur. Le mieux est lâennemi du bien : ne faites que ce qui est hautement utile.
I-B. Explications et objectifs▲
Si lâobjectif premier de ce tutoriel est ÃĐvidemment la prÃĐsentation des WebExtension, de leur intÃĐrÊts, de leurs constructions et de certains ÂŦ piÃĻges Âŧ, nous allons nous attarder sur quelques points spÃĐcifiques dâun sujet par ailleurs bien trop vaste.
Ce tutoriel expliquera par exemple comment modifier les requÊtes reçues (en rÃĐalitÃĐ, vous pouvez ÃĐgalement contrÃīler celles envoyÃĐes, les intercepter, en produire dâautresâĶ). Cependant ce nâest pas la modification en tant que telle qui est intÃĐressante mÊme si, pour beaucoup de dÃĐveloppements en Web, câest dÃĐjà un changement de paradigme. Câest apprÃĐhender une vision radicale des ÂŦ pages Âŧ du Web au profit dâune gestion des ressources offertes par le rÃĐseau et de lâutilisation de lâensemble des ÂŦ contenus Âŧ du navigateur.
La motivation des points abordÃĐs & des scripts liÃĐs est dâagir en lieu et place de ce qui est prÃĐvu par le serveur (ou le service) Web de lâautre cÃītÃĐ de la connexion. Câest dÃĐnaturer non seulement quelques aspects graphiques mais aussi en violer le fonctionnement natif : nous verrons dans une seconde partie, quâil nâest pas toujours possible de se contenter de la seule interception du code source et quâil est parfois prÃĐfÃĐrable et plus facile, de modifier à la marge le comportement ÂŦ naturel Âŧ des pages. Câest tout autant un monde possible qui sâouvre que dâalertes à garder à lâesprit.
âĶ ÂŦ Je croyais que la rÃĻgle dâor indiquer quâaucune communication ne devait avoir lieu avec un serveur inconnu et son contenu ? Une page en exÃĐcution nâentre pas ce registre ? Âŧ Câest vrai, mais il sâagit là dâun cas bien plus restrictif : nous utilisons un contenu dÃĐjà rÃĐcupÃĐrÃĐ par ailleurs par le navigateur. Certains garde-fous existent. Câest-à -dire quâà aucun moment nous nâagirons avec le serveur à proprement parler, et les scripts envoyÃĐs depuis le serveur, ne peuvent agir sur notre WebExtension (WebExt) : tout est fait à partir des ressources locales et exploitÃĐes depuis les seules ressources du navigateur. Cela reste un risque, mais moindre que celui dâentamer en direct lâinterception HTTP (nous, nous agirons toujours au niveau de la source HTML dans nos exemples).
Dans la premiÃĻre partie donc, du contenu HTML classique, repris et modifiÃĐ, avec un site que jâai sÃĐlectionnÃĐ car lâinformation est accessible pour tous mais au prix dâune grande lourdeur de page. Ici cette modification va annuler une partie aussi de la surveillance et du tracking â du suivi en bon français â publicitaire. Par la suite câest à Twitter que nous nous occuperons, mais cela pourrait Être Facebook ou tout autre rÃĐseau social. Dans les deux cas, des nouveaux services peuvent Être associÃĐs, particuliÃĻrement en local.
Enfin garder à lâesprit quâil nây a aucun ÂŦ hack Âŧ dans le code que je vous propose : vous ne verrez jamais davantage que ce que le serveur envoie â je nâentre dâailleurs pas ici sur lâaction de nÃĐgociation des protocoles. Cependant ce qui est est exposÃĐ ici enfreint clairement la plupart des CGU â Conditions GÃĐnÃĐrales dâUtilisation - des sites et des services : je vous incite à ne pas reproduire, en dehors dâun cadre pÃĐdagogique limitÃĐ, cette mise bout-à -bout des possibilitÃĐs des WebExtensions sans en comprendre les enjeux lÃĐgaux qui sâappliquent dans votre pays.
I-B-1. Rappel▲
Lâauteur rejette par avance tous les problÃĻmes de sÃĐcuritÃĐ ou de stabilitÃĐ, ou de contournement des CGU, occasionnÃĐs par lâutilisation des exemples fournis dans le prÃĐsent article, qui se veut strictement de sensibilisation et dâapprentissage.
I-C. Un des outils utilisÃĐs : le XSL▲
I-C-1. XSL : un ÂŦ ancÊtre Âŧ si performant▲
Depuis longtemps le HTML nâest plus dÃĐrivÃĐ du XML, mÊme sâil en garde une ergonomie gÃĐnÃĐrale : les balises meta par exemple, dans le head, ne sont pas fermÃĐes ; câest pour cela que lâon parle souvent de soupe en ÃĐvoquant le code (la ÂŦ source Âŧ) HTML. Parser (ou traduire en bon français) du HTML avec un outil conçu pour le XML ÃĐchouera. Cela ne veut pas dire que le HTML ne peut pas passer à du XML ou lâinverse â mais ce nâest pas forcÃĐment sans consÃĐquences. Il existe par ailleurs ÂŦ dâanciennes Âŧ variantes comme le XHTML, qui elles reprennent les canons du XML.
Nous ne verrons pas ici ces ÂŦ bizarreries Âŧ de HTML vis-à -vis du XML : contentons-nous de savoir quâun lien entre les deux existent et que le passage de lâun à lâautre peut Être aussi possible, notamment en JavaScript.
XSL â eXtensible Stylesheet Language â est aussi vieux que le XML. Il est une feuille de route, une notice de changements à opÃĐrer du XML en entrÃĐe, vers tout autre langage ÂŦ compatible Âŧ avec le XML (ou qui en est dÃĐrivÃĐ : PDF, HTML, etc) ou du XML pur. Ces changements sont des transformations, dÃĐfinies par plusieurs normes. XSL sâappuie sur XPath, en quelque sorte la grammaire dâune ÃĐcriture des liens et des parentÃĐs entre les ÃĐlÃĐments XML.
JavaScript, lorsque vous utilisez un document ÂŦ DOM Âŧ (compatible avecâĶ), sâappuie en grande partie sur des rÃĐalisations, sur un ÂŦ esprit Âŧ XML pour gÃĐrer lâarborescence de HTML. Celle-ci est simplement moins stricte, car lâhÃĐritage de HTML a ÃĐtÃĐ imprÃĐgnÃĐ â câest là une opinion toute personnelle â dâannÃĐes de dÃĐrives dâIE (Microsoft) et de raccourcis pour de mauvaises raisons des dÃĐveloppeurs du Web par la suite.
Il nây a pas dâincompatibilitÃĐ Ã utiliser XML en entrÃĐe pour produire du HTML, y compris la 5e version du nom. Avec un peu de verve, une de mes actualitÃĐs ÃĐvoquait ces liens et lâutilisation des transformations pour gÃĐnÃĐrer des pages cÃītÃĐ client. Nous utiliserons un principe similaire ici, en partie à cause dâun cadre avec des diffÃĐrences de contraintes vis-à -vis de ce quâest le Web classique, celui cÃītÃĐ client ÂŦ page Âŧ.
En rÃĐsumÃĐÂ :
- XML est un format de donnÃĐes statiques, tout comme HTML, qui hÃĐrite de certaines propriÃĐtÃĐs de XMLÂ ;
- XSL est un format de donnÃĐes des transformations à faire sur XML ;
- XPath permet des opÃĐrations de parcours complexe dâune arborescence XML. On parle ÃĐgalement de ÂŦ localisation Âŧ dans un arbre pouvant Être reprÃĐsentÃĐ comme des ensembles dâÃĐlÃĐments imbriquÃĐs ;
- Lâensemble est mixÃĐ par un moteur dÃĐdiÃĐ (il en existe plusieurs), à partir dâune mÊme norme, qui dÃĐfinit en outre des fonctions appelables au sein de XSL.
I-C-2. Pourquoi utiliser XSL pour les pages HTML à traiter ?▲
Nous verrons plus loin dans cet article des limitations fortes dans le cadre des WebExt, notamment du cÃītÃĐ de lâÃĐvaluation dâexpressions ; je nâentre pas ici dans le dÃĐtail. Gardons pour principe quâen dehors de lâutilisation dâun pseudo-langage â avec le temps de dÃĐveloppement / test, la complexitÃĐ vis-à -vis de la finalitÃĐ et la courbe dâapprentissage cÃītÃĐ utilisateur ; bref caduque dans notre cas â, peu de solutions existent.
Or un code source HTML reçu dâun serveur, mÊme avec un pattern matching des URL, reste trÃĻs variable en fonction de chaque site et en fonction de chaque page sur un site. Il y a toujours la possibilitÃĐ de faire un seul et mÊme ÂŦ moteur Âŧ pour rÃĐcupÃĐrer lâinformation intÃĐressante (et câest par exemple offert avec certains navigateurs par le biais du mode ÂŦ lecture Âŧ), mais cela reste de lâarbitraire du dÃĐveloppeur : peut-Être que lâutilisateur a dâautres souhaits, dâautres besoins.
Pour donner un peu de souplesse dans un tel cas, le XSL est le meilleur. Pas le plus simple, pas le plus facile, pas le moins fastidieux, mais probablement le plus efficace. Si seule la premiÃĻre version de la norme est implÃĐmentÃĐe largement dans les navigateurs (tous pour ceux qui supportent les WebExt), la seconde version, bien plus pointue et astucieuse, nâest pour ainsi dire pas disponible sauf à passer par des tiers.
De plus le XSL nâest jamais quâune chaÃŪne de caractÃĻres qui se stocke donc trÃĻs bien (soit par stockage.local soit par IndexedDB), se parse en Javascript sans difficultÃĐ et sâapplique à un objet Document (DOM).
Alors comment faire ?
II. PremiÃĻre partie â Bien plus large que le ÂŦ Web Âŧ▲
II-A. Pour quel navigateur ?▲
Comme vous lâaurez dÃĐsormais compris, point de serveur ou de connexion dans cet article. Tout se passe exclusivement entre votre navigateur et vous. Jâutilise ici Firefox, mais sachez quâavec trÃĻs peu dâadaptations, la quasi-totalitÃĐ de ce que jâindique est utilisable directement sous Chrome. En effet les WebExtensions sont rÃĐgies par une norme qui dÃĐfinit les API utilisables ainsi que les diffÃĐrents contextes dâexÃĐcution et sont supportÃĐes et dÃĐveloppÃĐs par les principales ÃĐquipes de dÃĐveloppeurs des navigateurs.
En bref, ce qui est commun ou diffÃĐrent entre navigateurs :
- tous utilisent principalement lâasynchronisme (callback pour Chrome, promise pour Firefox et Opera)Â ;
- le fichier de ÂŦ dÃĐcouverte Âŧ et de configuration peut avoir quelques variations dâun navigateur à lâautre. Cependant ce nâest pas nÃĐcessairement une limite, car une bonne pratique est de sÃĐparer rapidement le projet en un tronc commun qui sera dÃĐclinÃĐ par navigateur, afin de respecter la procÃĐdure de publication ;
- tous utilisent les mÊmes droits (et les mÊme portÃĐes de droits) à quelques nuances ;
- les WebExtensions sont publiables par un rÃĐseau certifiant et sÃĐcurisant a minima, les WebExtensions auprÃĻs des utilisateurs (ce qui nâempÊche absolument pas dâutiliser un autre canal ou une installation directe).
II-A-1. Comment savoir si mon navigateur est compatible ?▲
Simplement : sâil supporte les WebExtension, notamment à partir de la version 57 de Firefox (en rÃĐalitÃĐ antÃĐrieurement, mais lâAPI est rÃĐduite car le multiprocessus nây est pas encore la norme) et la version 25 de Chrome (mÊme les WebExtensions nâÃĐtaient pas alors dans une version normÃĐe dÃĐfinitive), alors il est trÃĻs probable que votre navigateur supporte la plupart de ce que je dÃĐcris dans cet article.
II-B. DÃĐmarrer le projet▲
Tout dâabord crÃĐer un dossier dÃĐdiÃĐ : inutile de vous prÃĐoccuper si ce dernier est accessible par un ÃĐventuel serveur ; il pourra fort bien Être sur le bureau. Vous crÃĐerez un certain nombre de fichiers dans ce dossier qui sera la racine votre WebExt et que vous laisserez vides pour lâinstant :
- /manifest.json : ce sera le fichier ÂŦ de dÃĐcouverte Âŧ de lâextension par le navigateur, et de configuration. Dans notre cas, il y dÃĐfinira les scripts à charger, les droits et permissions, ainsi que des ÃĐlÃĐments de prÃĐsentation. Sa seule prÃĐsence pour tous les navigateurs est obligatoire ;
- /background.js : un script dit dâarriÃĻre-plan, qui sera complÃĐtÃĐ au fur et à mesure de lâavancÃĐe du tutoriel ;
- /logo.png : vous pouvez y mettre une image comme vous le souhaitez (au format PNG naturellement).
Vous devez ensuite ÃĐditer le fichier manifest.json, en gardant à lâesprit que ce fichier, rÃĐellement indispensable, doit Être construit avec soin. Il devra notamment Être toujours valide au format JSON. Pour que lâextension soit valide au dÃĐmarrage du projet, ÃĐditons le fichier comme suit :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
{
"manifest_version": 2,
"name": "ControlePage",
"version": "1.0",
"description": "ContrÃīler les requÊtes grÃĒce aux 'pattern matching'.",
"icons": {
"48": "logo.png"
},
"permissions": [],
"background": {
"scripts": [
"background.js"
]
}
}
Peu de choses à dire je crois, lâensemble se comprenant facilement. A noter tout de mÊme que la version dâun manifest doit toujours Être à ÂŦ 2 Âŧ (compte tenu que câest une nouvelle ÂŦ maniÃĻre Âŧ de produire des extensions vis-à -vis de lâexistant, dÃĐnommÃĐes rÃĐguliÃĻrement les add-ons sous Firefox). Ãgalement la racine de la WebExtension sera dans notre cas toujours le dossier dans lequel est le manifest.
Il ne reste quâà charger lâextension dans le navigateur (ÂŦ extension Âŧ â paramÃĻtres (la piÃĻce crantÃĐe) â ÂŦ Installer un module depuis un fichier Âŧ). Vous devriez toujours ÃĐviter de travailler sur votre navigateur du ÂŦ quotidien Âŧ, celui avec vos profils connectÃĐs. Il nây a pas de ÂŦ retour en arriÃĻre Âŧ si malencontreusement votre WebExtension est mal dÃĐveloppÃĐe, et provoque une erreur ou une action non-voulue.
Vous pouvez aussi utiliser Web-ext (un module NodeJS), qui permet de recharger automatiquement la WebExt dans le navigateur, pratique pour une phrase de dÃĐveloppement et de debugging. Web-ext utilise par ailleurs, au moins sous Linux, un profil vierge pour dÃĐmarrer.
Avant dâaller plus en avant, notamment ÃĐditer le fichier background.js, nous devons faire un point sur les diffÃĐrents types et contextes dans lequel agissent habituellement les scripts JS. Loin des canons habituels du WebâĶ
II-B-1. Comprendre JavaScript dans un navigateur moderne : portÃĐe et contextes▲
Les WebExtensions sont une bonne introduction à la richesse â et son pendant, un relatif bazar â quâentoure dÃĐsormais le langage ÂŦ du Web, pour le Web Âŧ à tous les niveaux. La banche de JS à la sauce NodeJS, et son cÃĐlÃĻbre moteur V8, est probablement lâun des aspects les plus connus. Pourtant lâÃĐvolution touche ÃĐgalement les clients.
Jâai regroupÃĐ ici les principales familles de ce cÃītÃĐ ÂŦ client Âŧ et qui nous intÃĐressent dans le cadre dâune utilisation sur le navigateur. à chaque fois câest bien le mÊme langage (une mÊme version), le mÊme environnement (le navigateur) mais pas le mÊme contexte (et donc pas la mÊme disponibilitÃĐ dâAPI), portant aussi sur la portÃĐe de certaines variables (en ÃĐcriture et en lecture).
Ce tableau qui tente une synthÃĻse probablement trÃĻs critiquable et partielle, sâappuie sur la documentation du MDN et est une construction personnelle. En jaune, vous trouverez les scripts ÂŦ habituels Âŧ, insÃĐrÃĐs dans une page et que nous avons lâhabitude de voir dans les tutoriels et autres exemples. En gris, ceux sur lesquels sâarrÊtera principalement cet article.
|
PortÃĐes |
Cadres dâutilisation |
Familles techniques (groupes de portÃĐes ou classes dÃĐrivÃĐes) |
Sous-familles techniques
|
AccÃĻs aux DOM / Ã certains objets |
|---|---|---|---|---|
|
PortÃĐe principalement interne au navigateur (script à vocation asynchrone ; correspond à une notion de ÂŦ services Âŧ) |
ArriÃĻre-plan de WebExt |
Script(s) dâune page fictive ou non ; chargÃĐs en permanence au dÃĐmarrage du navigateur et dÃĐfini par le manifest |
â Pas de DOM vÃĐritable : les scripts peuvent Être appelÃĐs indÃĐpendamment dâune page et celle-ci nâest de toute façon quâune page ÂŦ virtuelle Âŧ |
|
|
ArriÃĻre-plan de page |
ÂŦ Worker Âŧ |
ServiceWorker : |
â Pas dâaccÃĻs direct à un DOM |
|
|
PortÃĐe principalement interne à une ou plusieurs pages |
Avant-plan et arriÃĻre-plan dâune seule page |
ÂŦ Web Âŧ Worker : |
â Pas dâaccÃĻs direct à un DOM |
|
|
Avant-plan et arriÃĻre-plan entre plusieurs pages dâun mÊme domaine |
SharedWorker : |
â Pas dâaccÃĻs direct à un DOM |
||
|
Script ÂŦ de page Âŧ, que lâon qualifiera dâavant-plan de page |
â AccÃĻs direct au DOM |
|||
|
PortÃĐe mixte |
â AccÃĻs direct à un DOM |
â AccÃĻs direct à un DOM |
||
Ainsi nous pouvons tirer de ce tableau et de la documentation, quelques points-clÃĐ pour bien comprendre quoi utiliser et quand en trois grands points (donc rÃĐsumÃĐ arbitraire)Â :
-
la portÃĐe du script, câest-à -dire sur quel aspect dâune ressource (page, DOM, bases de donnÃĐes, etc) ou dâune interface (Workers, etc) il agira. Par exemple pour un script de contenu :
- a-t-il un accÃĻs direct ou indirect à une ressource â accÃĻs direct à lâespace de stockage de la WebExtension et du DOM de la page oÃđ il sâexÃĐcute ;
- partage-t-il la possibilitÃĐ directe dâune lecture et/ou ÃĐcriture de variable â si un script de contenu a accÃĻs au DOM, il ne verra pas et ne peut modifier les variables associÃĐes à lâobjet Document ou Window des scripts de page ;
-
sa nature, câest-à -dire sâil est à vocation strictement synchrone, mixte ou strictement asynchrone :
- un code bloquant dans une vocation strictement synchrone bloquera tout le script â ex. le fonctionnement originel de JS sur les navigateurs,
- un code bloquant dans une vocation mixte, peut bloquer tout ou partie dâun script ou lâutilisation dâune ressource â ex. actuellement sur un script de page qui utilise à la fois du code synchrone et de la gestion dâÃĐvÃĐnements, ainsi que des appels à des Workers,
- un code bloquant dans une vocation strictement asynchrone pourra retourner une erreur et celle-ci peut-Être silencieuse â ex. script dâarriÃĻre-plan dâune WebExtension (lâerreur apparaÃŪt dans les logs seulement du navigateur) ou script de ServiceWorker gÃĐrant un cache (lâerreur apparaÃŪt dans les log de la page oÃđ il est lancÃĐ) ;
- son intÃĐrÊt ; câest-à -dire à quoi il est traditionnellement assignÃĐ, comme je lâindique plus haut. Son intÃĐrÊt est souvent liÃĐ au moment du dÃĐclenchement dans lâensemble des ÃĐvÃĐnements possibles sur un navigateur (qui ne se limite pas, encore une fois, à quelques pagesâĶ !).
II-B-2. Phase 0 - DâoÃđ lâon vient ; oÃđ lâon va ▲
Le choix dâun site pour cette premiÃĻre partie, nâa pas ÃĐtÃĐ anodin. Il sâagit dâun site commercial, avec ÃĐnormÃĐment de scripts de pages internes et externes, notamment publicitaires, de nombreuses ressources mais un code qui reste relativement clair et un contenu structurÃĐ (pouvant Être tabularisÃĐ pour lâexercice). Surtout, la mise à jour intervient à un rythme rÃĐgulier (une fois par jour), qui nous permet de faire des tests sur un temps long et pouvant facilement Être apprÃĐhendÃĐ. Enfin,un point & non des moindres : vous pouvez tester indiffÃĐremment par HTTP et HTTPS sur cette page, qui retourne la mÊme chose (et ainsi constater quâeffectivement, vous nâagissez pas ici sur la connexion mais bien sur la requÊte qui transite sur la connexion).
Voici lâURL sur laquelle travailler (les autres pages ne nous intÃĐresseront pas ici)Â : http://www.programme-tv.net/programme/programme-tnt.html
Voici que vous pourriez voir sans transformation de la page :

Voici ce que vous devriez voir aprÃĻs transformation :
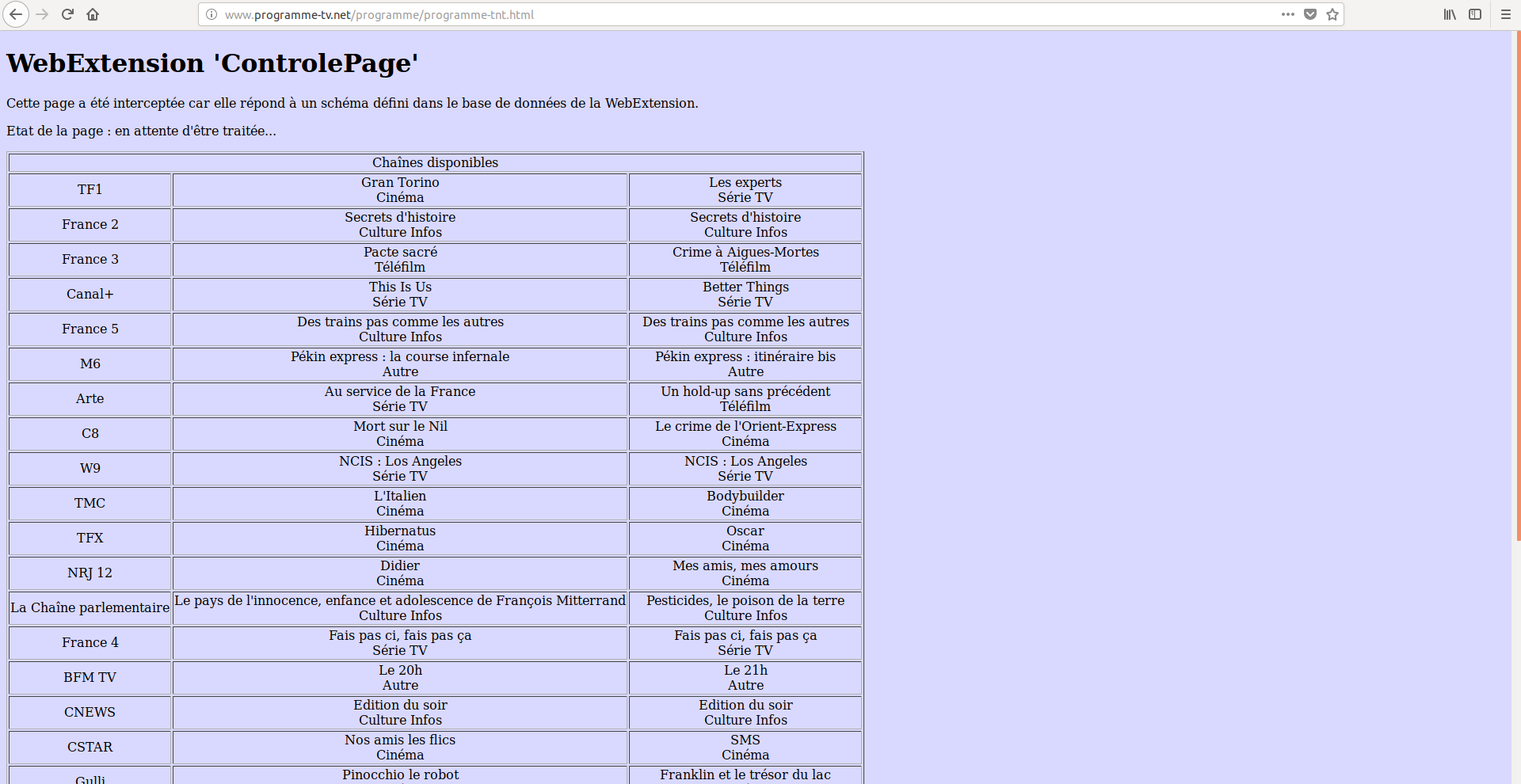
Notez quâaucun script de la page initiale (celle renvoyÃĐe par le serveur, avec les scripts publicitaires) nâaura ÃĐtÃĐ finalement chargÃĐ aprÃĻs la transformation. Pour arriver à ce rÃĐsultat, nous aurons les ÃĐtapes suivantes :
-
avant la requÊteâĶ
- ajouter une fonction aux ÃĐcouteurs dâÃĐvÃĐnement,
- procÃĐder à un filtrage par motif (pattern matching) ainsi que par type (ici les codes sources des pages dites main_frame, jamais des frames incluses dans une page) ;
-
au niveau de la requÊte en elle-mÊmeâĶ
- rÃĐcupÃĐrer le corps de la rÃĐponse, pour en produire du ÂŦ texte Âŧ, qui sera ÃĐchappÃĐ et introduit dans une page HTML type ;
- renvoyer cette page type comme rÃĐponse à interprÃĐter dans le bon format ;
-
au niveau de la page (du code source) renvoyÃĐeâĶ
- une fois cette page type avec le contenu original de la requÊte chargÃĐe dans lâonglet, procÃĐder à lâanalyse (DOMParse) et aux transformations XSL,
- rÃĐinjecter dans la source HTML transformÃĐ, son objet DOM, dans la page qui a servi de support.
Pourquoi traiter les transformations XSL au sein dâun onglet et non directement lors de la rÃĐception du contenu original ? Plusieurs raisons mâont poussÃĐ Ã ce choix :
- ne pas perdre du temps : lorsque lâutilisateur demande une page, lorsquâil demande une URL ou parce quâelle est chargÃĐe à lâouverture dâun onglet, il souhaite connaÃŪtre lâÃĐtat dâavancement. Renvoyer une page type, qui indique tout de suite lâinterception, lâÃĐtat actuel de chargement, la possibilitÃĐ dâannuler la transformation et lâavancement de la transformation, puis se chargera dâÊtre le ÂŦ support Âŧ, permet à la fois une information complÃĻte et une meilleure maÃŪtrise ;
- circonscrire les erreurs : si votre script rencontre une erreur sur la transformation dâune page, mieux vaut quâun plantage ou un ralentissement soit au niveau de lâonglet quâau niveau de la WebExt ;
- fractionner le dÃĐveloppement : la rÃĐcupÃĐration est un processus diffÃĐrent de la transformation, gÃĐrÃĐ par un autre script. Une ÃĐvolution de lâun ne touche pas lâautre et pour la relecture par un tiers, en plus des commentaires, les scripts ainsi ÂŦ dÃĐcoupÃĐs Âŧ sont moins indigestes.
Pour les transformations, nous utiliserons les seules fonctions natives JS du navigateur, en passant dâun code source HTML Ã un objet Document puis la transformation de ce dernier avec un contenu XSL parsÃĐ.
II-B-3. Phase 1 - DÃĐtecter les requÊtes intÃĐressantes▲
Dans notre phase prÃĐcÃĐdente, nous avons installÃĐ une WebExt vide, sans aucune permission, ainsi quâun fichier de script dâarriÃĻre-plan. Pour dÃĐtecter des requÊtes intÃĐressantes, il ne sâagit pas juste de ÂŦ lire Âŧ lâURL et de la comparer à un motif : encore faut-il, une fois dÃĐtectÃĐe, pouvoir extraire de la ressource qui y sera associÃĐe (ici du contenu HTML), ce qui nous intÃĐresse. Et mieux : modifier cette ressource.
Il nous faudra aussi stocker notre transformation XSL, qui sera appliquÃĐeâĶ Ici nous nâen stockerons quâune, pour lâexemple, qui sera ÃĐditable dans la seconde partie. Pour une seule transformation, ouvrir un espace de stockage, au dÃĐtriment dâune simple variable, nâest pas utile. Câest pourquoi dans la seconde partie, nous pourrons ÂŦ rentabiliser Âŧ cet espace ouvert en pouvant crÃĐer de nouvelles transformations. Jâai ÃĐgalement utilisÃĐ lâespace de stockage pour une page type, jâen dÃĐtaillerai plus loin la raison.
Mettons donc tout dâabord les permissions nÃĐcessaires à notre script. Nâoubliez pas quâà chaque ÃĐtape, si vous nâutilisez pas lâoutil web-ext mentionnÃĐ plus haut, vous devrez recharger manuellement votre WebExt afin que les modifications soient prises en compte.
La partie permissions du fichier manifest.json, doit dÃĐsormais ressembler à cela :
2.
3.
4.
5.
6.
7.
8.
9.
{
"permissions": [
"unlimitedStorage",
"storage",
"webRequest",
"webRequestBlocking",
"<all_urls>"
]
}
Les deux premiers items vous permettent dâaccÃĐder à une ressource de stockage pour la WebExt â câest-à -dire indÃĐpendamment des autres espaces de stockage notamment ceux liÃĐs aux domaines visitÃĐs. En rÃĐalitÃĐ, Firefox considÃĻre lâID de lâextension comme un domaine à part entiÃĻre, et repose donc sa stratÃĐgie de stockage pour la WebExt comme il le ferait pour nâimporte quel site Internet. Lâitem unlimitedStorage nâa pas dâutilitÃĐ dans notre exemple ; je le donne à titre dâinformation. Il ne sâapplique pas dâailleurs au stockage sync mais seulement aux stockages locaux â c sync ÃĐtant celui qui est synchronisÃĐ entre les diffÃĐrentes instances connectÃĐes à un mÊme compte (ex. Firefox Sync ou votre compte Google pour Google Chrome) et dont les rÃĻgles de quota sont gÃĐrÃĐs par ces mÊmes services.
â Bon à savoir : Firefox, comme dâautres navigateurs, ne garantit pas la prÃĐservation ÂŦ impÃĐrative Âŧ des donnÃĐes â c-à -d que vous pourriez avoir des donnÃĐes effacÃĐes sans que la navigateur ne le demande à la WebExtension voire ni mÊme ne lâalerte. Un critÃĻre temporel (lâaccÃĻs le plus vieux à une base) est utilisÃĐ, puis un effacement dans la base la plus ancienne sans critÃĻre prÃĐcis indiquÃĐ (alÃĐatoire?).
Si pour un poste fixe rÃĐcent, la quantitÃĐ de mÃĐmoire ÂŦ en dur Âŧ est bien plus que suffisante en dehors de certains usages (jeux, calculs scientifiques, etc) ; ce qui nâest pas le cas pour les pÃĐriphÃĐriques mobiles. Un paragraphe sera dÃĐdiÃĐ au cas des WebExtensions sur pÃĐriphÃĐrique mobile dans la conclusion de lâarticle.
Attention donc, à ne pas considÃĐrer cette base comme une base de donnÃĐes ÂŦ dÃĐfinitive Âŧ comme peut lâÊtre par exemple MySQL, qui arrÊtera simplement lâenregistrement de nouvelles donnÃĐes. Vous devez toujours considÃĐrer quâil sâagit ici dâun SGBD à vocation ÂŦ temporaire Âŧ ou au moins dâun systÃĻme ÂŦ incertain Âŧ, quand bien mÊme le cas nâaurait pas de raison de prÃĐsenter, par le simple fait quâil est possible.
Les autres items sont eux plus intÃĐressants et permettent le suivi de toutes les requÊtes (quel que soit le format de celles-ci, jây reviendrai), ainsi que leur manipulation comme peut Être traduit webRequestBlocking. Lâitem <all_urls> est en quelque sorte ÂŦ un opÃĐrateur Âŧ, que lâon peut retrouver dans dâautres parties des API WebExtension et dont lâusage implique une absence de restriction sur les URL pouvant Être ainsi ÂŦ gÃĐrÃĐes Âŧ, quel que soit le protocole (HTTP ou HTTPS). Attention, le domaine du magasin dâapplications pour Firefox ou pour Chrome, est naturellement inviolable par les WebExtension, afin dâÃĐviter toute manipulation, ainsi que certains protocoles liÃĐs au fonctionnement du navigateur (une WebExt ne peut pas, par exemple, agir sur ses propres requÊtes â ou globalement lorsquâil sâagit du protocole moz-extension://).
Au sein du fichier background.js, des ajouts sont à prÃĐvoir. Je vais tenter de rÃĐsumer schÃĐmatiquement comme lâutiliser pour le mieux :
- en qualitÃĐ de script dâarriÃĻre-plan lorsque le navigateur dÃĐmarre avec une WebExt dÃĐjà installÃĐe, il est dÃĐclenchÃĐ au moment du lancement du navigateur. En rÃĐalitÃĐ ce dernier est dÃĐjà lancÃĐ et votre script intervient entre la fin du chargement des principaux organes du navigateur, et le dÃĐmarrage du lancement du ou des premiers onglets affichÃĐs à lâutilisateur (le navigateur ÃĐtant ici un ÂŦ client Âŧ des donnÃĐes). Câest important de se rappeler cela : vous ne pourrez jamais Être avant ce moment du chargement, par ce qui est offert dans un script dâarriÃĻre-plan. Dans certains cas, notamment lorsque des WebExt agissent sur une mÊme fonction, vous ne pouvez donc pas Être certains que ce qui arrive à votre WebExt nâa pas dÃĐjà ÃĐtÃĐ modifiÃĐ ou stoppÃĐ par une autre(1) ;
- contrairement à dâautres scripts qui doivent Être ÂŦ vÃĐritablement Âŧ asynchrones (notamment les scripts de ServiceWorker à vocation de gestion dâun cache local), les scripts dâarriÃĻre-plan sont tout à fait synchrones (donc pouvant Être bloquÃĐs par une opÃĐration) et sont surtout utiles pour formaliser (au sens dâune dÃĐclaration de fonction) et enregistrer les interceptions dâÃĐvÃĐnements.
Nous allons dâabord dÃĐclarer une fonction â listener â qui servira à traiter les requÊtes intÃĐressantes. Non pas à les filtrer, car cela nâest rendu possible que par lâenregistrement dâune ÃĐcoute dâÃĐvÃĐnement qui rÃĐagit aux requÊtes correspondant à un motif (pattern matching) que nous verrons plus loin :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
18.
19.
browser.SurveilleURLs = [
"*://www.programme-tv.net/programme/programme-tnt.html"
]; // â l'objet 'browser' est lâÃĐquivalent de 'window' pour un script de page, et tous les appels de toutes les API des WebExt passent par cet objet
function listener(details) {
let filter = browser.webRequest.filterResponseData(
details.requestId
);
let tabBuffer = []; // â on reçoit du binaire ! Pas du texte
filter.ondata = event => {
tabBuffer.push(event.data); // â à chaque rÃĐception dâune portion de la rÃĐponse, on ajoute cette portion de code binaire à notre tableau qui sert de 'buffer'
}
filter.onstop = event => { // â fin de la rÃĐception des portions
var source = new Blob(tabBuffer, {type : 'text/html'});
console.log(source);
filter.write(source); // â on renvoie directement la source sans modification pour la poursuite
filter.disconnect(); // â on arrÊte lâÃĐcoute
}
}
Dans la console du navigateur et pas la console dâune page ouverte (ÂŦ DÃĐbogger des modules Âŧ dans le menu gÃĐnÃĐral des WebExt), vous verrez le contenu de la source ainsi interceptÃĐe.
Cela devrait ressembler à cette ligne :
Blob { size: 276530, type: "text/html" }
Nous positionnons auparavant cette fonction dans un ÃĐcouteur dâÃĐvÃĐnement, grÃĒce à lâAPI offerte par webRequestBlocking :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
browser.webRequest.onBeforeRequest.addListener(
listener,
{
urls: browser.SurveilleURLs, // â mettre '<all_urls>' pour intercepter toutes les pages sources disponibles
types: [
"main_frame" // â seulement les pages ÂŦ sources Âŧ (pas les iframes, les images, scripts, CSS, etc). De toute façon leur chargement intervient sur instruction de la source : si celle-ci est modifiÃĐ, leur chargement nâexistera pas
]
},
[
"blocking"
]
);
Jâai choisi dâindiquer une interception avant la requÊte elle-mÊme â onBeforeRequest â, afin de nous assurer que cette requÊte, si elle aboutit (mÊme en cas de retour 404 ou 500), soit correctement ÂŦ ÃĐcoutÃĐe Âŧ et modifiÃĐe dans notre cas.
â Bon à savoir : il est souvent notÃĐ quâun ÃĐcouteur dâÃĐvÃĐnement est une fonctionnalitÃĐ du DOM pour les pages. Câest incomplet : le Document Object Model regroupe lâensemble des ÃĐvÃĐnements qui sont liÃĐs aux contenus et à leurs traitements au sein dâun logiciel (ici le navigateur). Câest en quelque sorte la mÊme ÂŦ recette Âŧ qui est appliquÃĐe pour chacun des ÂŦ ÃĐvÃĐnements Âŧ qui sont suivis (c-à -d schÃĐmatiquement un changement dâÃĐtat dâune fonction ou dâune variable), permettant dâunifier les ÃĐcouteurs et les interceptions.
Ainsi un DOM pour HTML est voisin dâun DOM pour des ÃĐvÃĐnement HTTP ou liÃĐ au fonctionnement du navigateur (ouverture dâun onglet, dâun menu, etc).
II-B-4. Phase 2 â Comprendre ce que lâon reçoit et ce que lâon ÃĐmet▲
Si votre WebExt est rechargÃĐe et que vous chargez la page surveillÃĐe, vous verrez dÃĐsormaisâĶ une magnifique page vierge (et une page normale partout ailleurs, sauf dans le cas <all_urls> ÃĐvidemment). IncomprÃĐhensible : nâa-t-on pas fourni le contenu avant de dÃĐsactiver notre interception ?
Le problÃĻme câest que ce que vous renvoyez ne correspond pas à ce que Firefox attend en terme de format (pas dâencodage, je parle bien de format). Il ne peut pas du binaire avec un flag (un drapeau) text/HTML, mais lâÃĐquivalent dâune chaÃŪne de caractÃĻre dans le langage JS.
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
18.
19.
20.
21.
function listener(details) {
let filter = browser.webRequest.filterResponseData(
details.requestId
);
let tabBuffer = []; // â on reçoit du binaire ! Pas du texte au sens JS
let encoder = new TextEncoder(); // â on va vraiment "comprendre" le binaire comme du texte
filter.ondata = event => {
tabBuffer.push(event.data);
}
filter.onstop = event => {
var source = new Blob(tabBuffer, {type : 'text/html'});
var reader = new FileReader();
reader.addEventListener("loadend", function(resultat) {
console.log(resultat.target.result); // ici le rÃĐsultat comme du texte "source" HTML classique
filter.write(encoder.encode(resultat.target.result));
filter.disconnect();
});
reader.readAsText(source);
}
}
Nous avons cette fois-ci la page qui est affichÃĐ Ã lâutilisateur et dans la console du navigateur, le texte ÂŦ source Âŧ HTML.
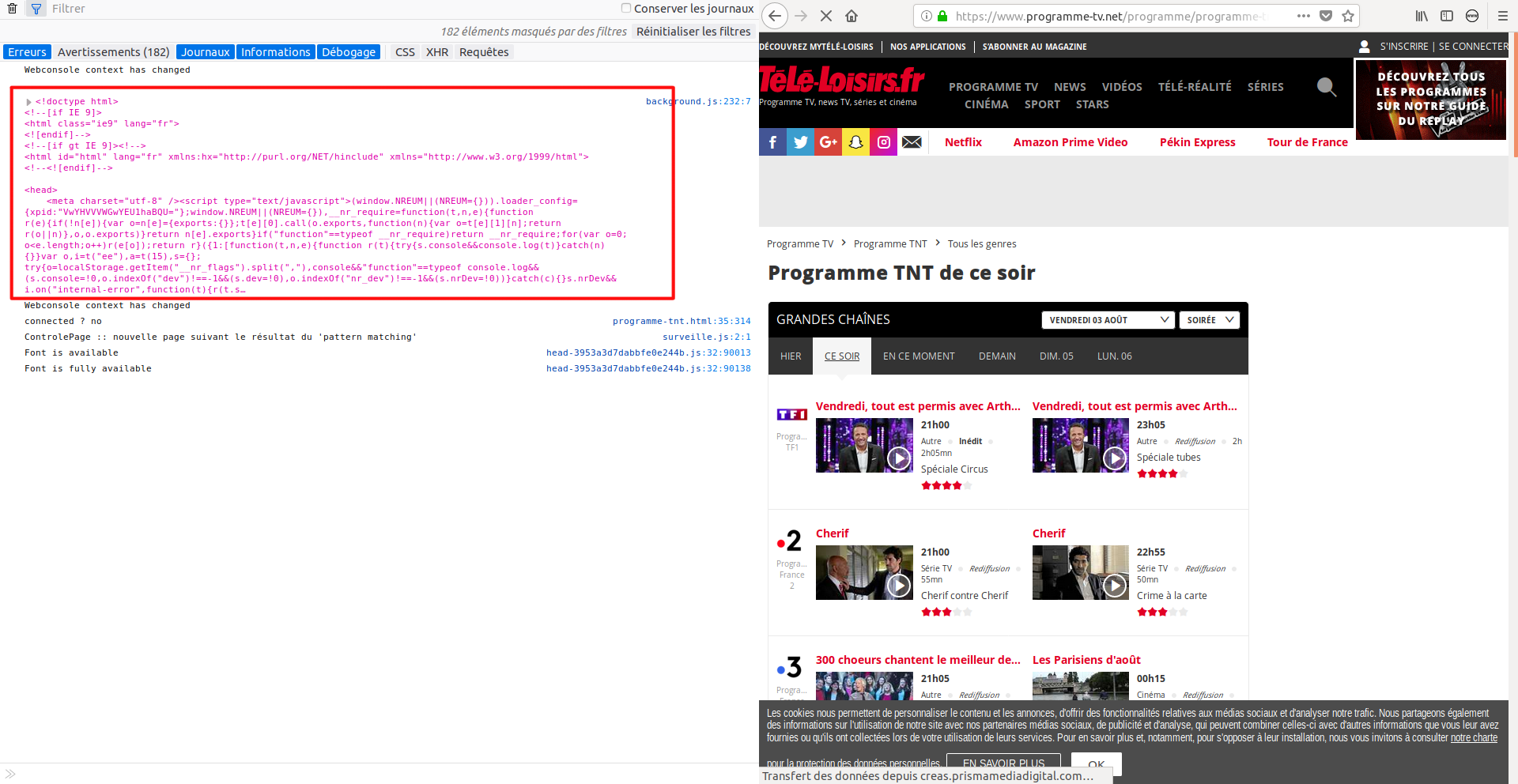
Je vais ÃĐgalement ajouter les lignes de code pour dÃĐfinir les objets dans lâespace de stockage Storage, que nous utiliserons aprÃĻs.
II-B-4-a. Code source actuel du fichier background.js▲
Pour cette premiÃĻre partie, voilà à quoi doit ressembler votre fichier. Nâoubliez pas quâici, à chaque chargement de votre WebExt (à lâinstallation et au redÃĐmarrage du navigateur si lâinstallation nâest pas temporaire), ce script sera lancÃĐ. Il ÃĐcrasera donc la transformation et la page par dÃĐfaut (vous devez rajouter une condition de non-existence si vous souhaitez empÊcher cela).
Jâai ajoutÃĐ ÃĐgalement un appel à lâespace de stockage pour charger une page ÂŦ support Âŧ par dÃĐfaut (cf browser.storage.local.get("page:defaut").then). Cela nâest pas pertinent sâil nây a quâune page ÂŦ support Âŧ type, qui peut Être utilement et seulement stockÃĐe dans une variable. Cependant si lâenvie vous prend de complÃĐter cette extension et de multiplier les pages supports, les transformations et les rÃĻgles associÃĐes, probablement aurez-vous besoin de faire appel à un espace de stockage (car le dÃĐchargement du script annulerait les modifications).
Prenez donc ce code comme une ÂŦ indication Âŧ dâune maniÃĻre de faire.
II-B-5. Phase 3 â Appliquer la transformation XSL▲
En ouvrant la console de la page, notez que jâai utilisÃĐ la balise template, dont jâÃĐvoquerai les qualitÃĐs et usages plus loin dans lâarticle, à dessein. Elle contient la source HTML originale de la requÊte, celle reçue du serveur, en version textuelle ÃĐchappÃĐe. Cette source originale est donc inerte et nâest pas traitÃĐe par le navigateur : lâonglet RÃĐseau de la console, vous indique ainsi quâaucun autre chargement de ressource ne se produit, ce qui est logique.
Ce qui est moins logique par contre, câest lorsque vous regardez dans ce mÊme onglet RÃĐseau, la rÃĐponse de la requÊteâĶ Vous trouvez la source originale et non notre page type ! Idem si vous ajouter view-source : à votre URL, indiquant que vous souhaitez voir seulement le contenu HTML. Seul lâInspecteur, onglet qui permet de parcourir le document HTML en temps rÃĐel, vous donne la page type. Pourquoi un tel comportement ? Dâabord une raison pratique : comme je vous lâindiquais, votre WebExt ne dispose que dâune ressource qui lui est attribuÃĐ par le navigateur, à un moment donnÃĐ. Le navigateur, lui, peut disposer de toutes les versions et donner à chaque composant une version ou une autre. Vous ne disposez pas ÂŦ totalement Âŧ de la capacitÃĐ Ã modifier un contenu ÂŦ original Âŧ, seulement dans un contexte un contenu ÂŦ dupliquÃĐ ÂŧâĶ
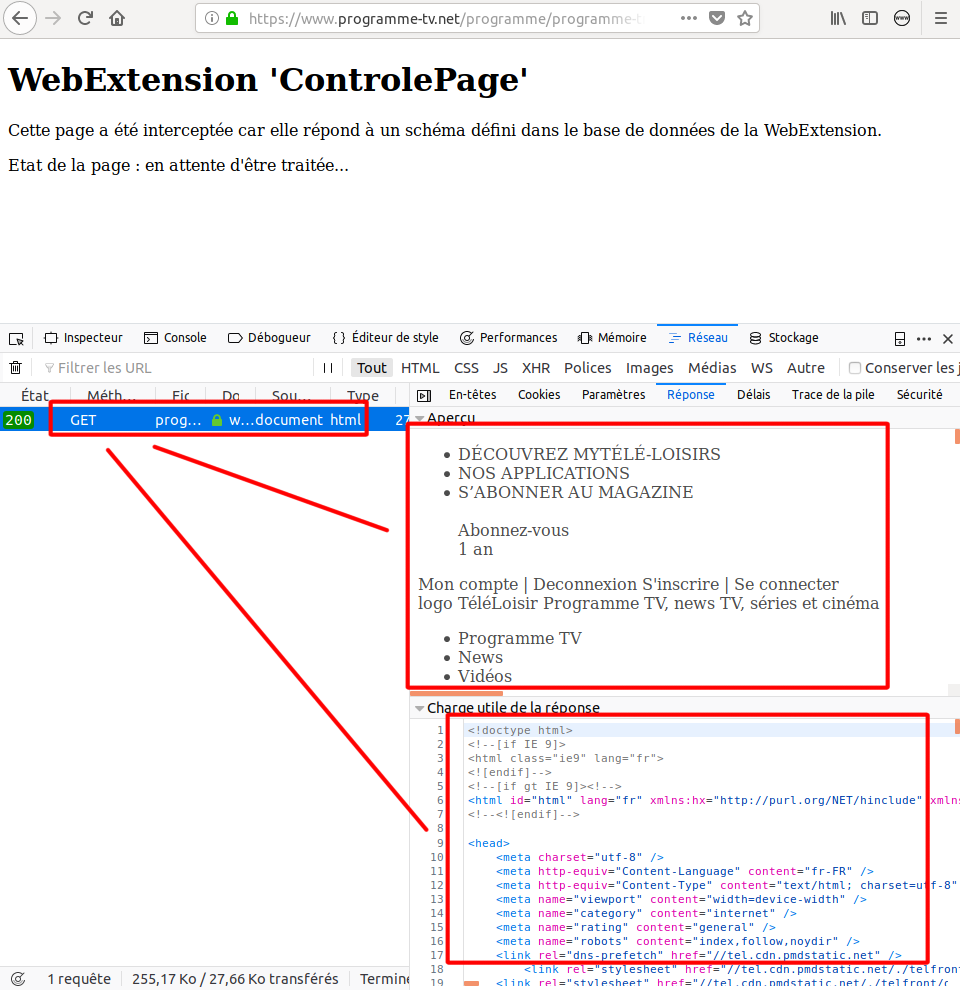
Câest ensuite une raison de sÃĐcuritÃĐ : lâutilisateur a un outil fiable, la console de la page, disponible pour chaque onglet, qui lui permet de voir si le traitement dâune page, sa source, est celle reçue du rÃĐseau ou a ÃĐtÃĐ modifiÃĐe. Ãvidemment sur le cas dâun site complexe comme le webmail de Google ou globalement des interfaces utilisant React ou ÃĐquivalent, une telle vÃĐrification nâa pas grand sens vu (1) la complexitÃĐ du code, (2) une gÃĐnÃĐration de chaque composant en temps rÃĐel.
Bien : votre page type sâaffiche mais toujours pas la transformation du contenu dÃĐsirÃĐ. Nous allons devoir ÂŦ injecter Âŧ du code Javascript quelque part. Et tant quâà faire, ÂŦ proprement Âŧ, sans utiliser le code source. Avec une WebExt, câest possible et câest facile, toujours grÃĒce aux motifs et aux ÃĐcouteurs dâÃĐvÃĐnements.
Voici un exemple de ce qui se passera : le navigateur ira chercher la page dâun cÃĐlÃĻbre site dâannonces en ligne (nous voyons dans la console de lâonglet que câest bien le cas), et notre WebExtension ne lui retournera que ce quâil lui chante :
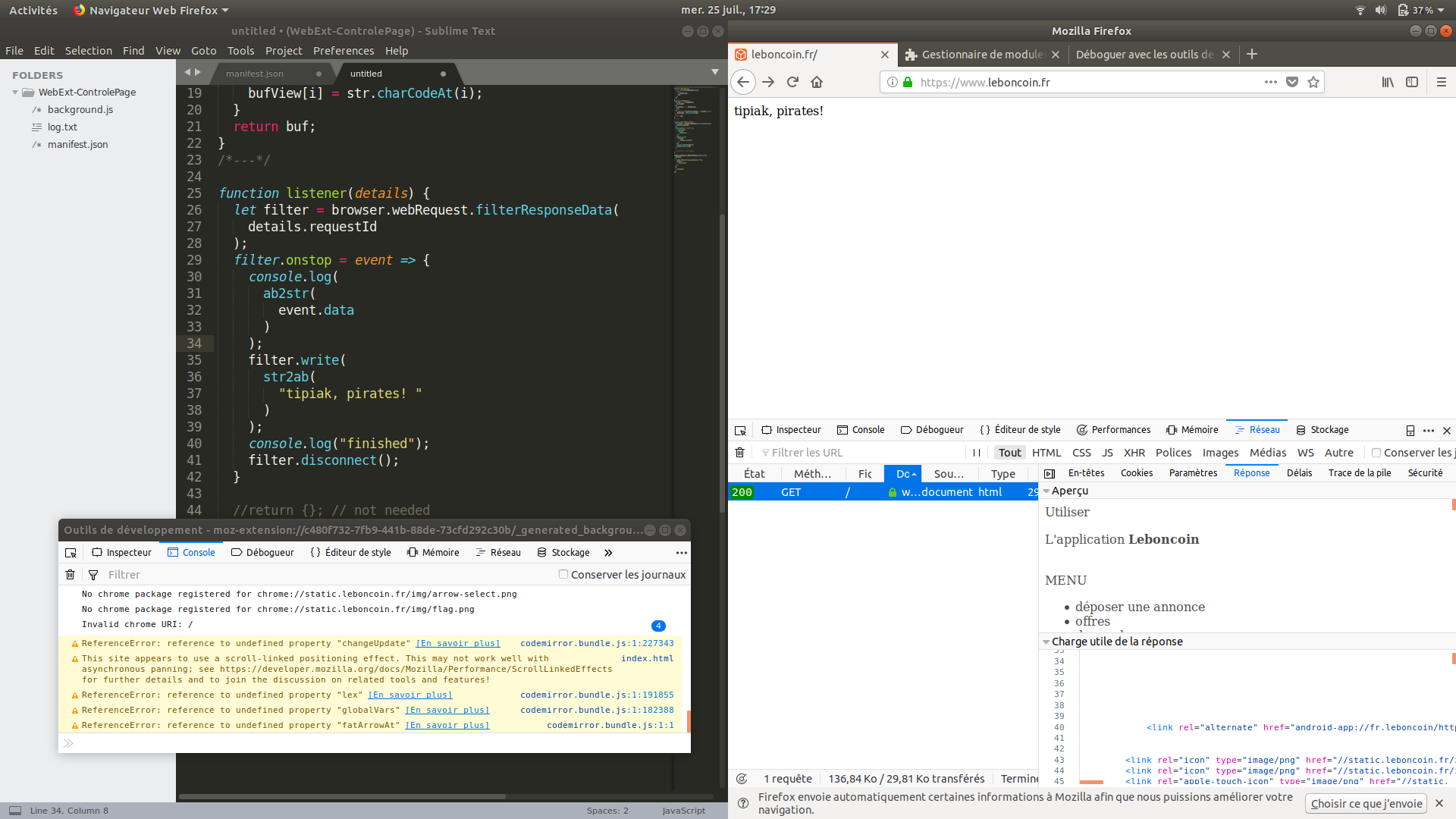
Allons-y ! Dans notre fichier background.js, insÃĐrez le code suivant :
2.
3.
4.
5.
6.
browser.contentScripts.register({
"js": [{file: "/surveille.js"}],
"css": [{file: "/commun.css"}],
"matches": ["<all_urls>"], // ou browser.SurveilleURLs pour faire du pattern matching
"runAt": "document_idle"
});
Vous avez dÃĐjà devinÃĐ lâintÃĐrÊt : crÃĐer le fichier à la racine de la WebExt, le fichier surveille.js et commun.css.
Dans ce dernier, modifiez le contenu avec le CSS suivant :
2.
3.
4.
5.
6.
7.
body {
background: rgba(0,0,255,0.15);
}
table * {
text-align: center;
}
Dans le premier, ajouter le code JS suivant :
console.log("ControlePage :: nouvelle page suivant le rÃĐsultat du 'pattern matching'");
âĶ puis regarder ce qui se passe pour chaque page, notamment sur Google oÃđ le fond de la page nâest plus blanc ! Avec le message dans la console de lâonglet.
Nous avons bien une insertion aprÃĻs le chargement du DOM et de lâensemble des ressources, de nos deux fichiers de WebExt. Logique ! lâattribut runAt dans lâobjet passÃĐ en argument de lâÃĐcouteur, dÃĐfinit le moment du chargement des ressources. ÂŦ Notre Âŧ CSS prend donc le pas sur le reste car câest le dernier a Être chargÃĐ (ÃĐcrasement des attributs). Nous verrons dans la seconde partie de cet article, les piÃĻges qui existent avec cette mÃĐthode et dans quel cas ne pas lâutiliser.
Vous pouvez repasser ["<all_urls>"] à la la variable browser.SurveilleURLs, ce qui restreindra cette injection à nos URL dÃĐfinies. Modifiez le script surveille.js avec le contenu suivant :
Ãa y est : votre page apparaÃŪt, belle et bien transformÃĐe par XSL. En modifiant la source de la transformation, vous agirez sur la prÃĐsentation. Avec CSS et Javascript, une fois injectÃĐs et par la suite avec des appels supplÃĐmentaires, vous pouvez ÃĐgalement maÃŪtriser plus en profondeur ces transformations. Vous pouvez ÃĐgalement rÃĐcupÃĐrer des ressources initialement demandÃĐes par la page dâorigine : tout est possible.
Avec, pourquoi pas, la possibilitÃĐ de vous faire un moteur des informations collectÃĐes, une sorte de moteur de recherche avancÃĐe, dans le contenu dâun historique qui ne se limite pas à la paire URL / titre de la page !
II-B-5-a. Et sans XSL malgrÃĐ tout ?▲
Câest toujours possible mais, comme nous le verrons dans cet article, lâÃĐvaluation dâexpression nâest pas possible au sein dâune WebExtension ce qui en limite considÃĐrablement lâusage (et mÊme si câest â presque â possible par le biais dâun hack sur la page, câest de toute façon totalement dÃĐcommandÃĐ).
Il faudra alors avoir recours à du JS codÃĐ ÂŦ en dur Âŧ dans le script qui, sâil nâest pas compliquÃĐ, nâoffre que peu le loisir dâÊtre modifiÃĐ par lâutilisateur :
Le rÃĐsultat sera conforme à ce que nous attendons. Notez quâil y a une subtile nuance pour les noms de chaÃŪnes, qui sont le contenu exact des titres, avec le prÃĐalable systÃĐmatique ÂŦ Programme deâĶ Âŧ :

II-C. Quelques rÃĐflexions supplÃĐmentaires▲
Dans la page renvoyÃĐe pour traitement dans lâonglet, pourquoi garder la source de la page ÂŦ originale Âŧ câest-à -dire le contenu HTML exact tÃĐlÃĐchargÃĐ du serveur ? Tout dâabord, et pour une ÂŦ mauvaise raison Âŧ, afin de ÂŦ basculer Âŧ de la page reconstruite à celle dâorigine sans ÂŦ recharger Âŧ â c-à -d redemander la source au serveur.
Une limitation cependant : les ÃĐvÃĐnements du navigateur, liÃĐs à la crÃĐation mÊme de lâonglet du document, qui lui nâest que modifiÃĐ et non recrÃĐÃĐ, peuvent gÃĐnÃĐrer des erreurs : les ÃĐcouteurs dâÃĐvÃĐnement peuvent ne pas Être dÃĐclenchÃĐs, ce qui peut rendre les scripts de la page inopÃĐrants.
Une autre raison, plus lÃĐgitime et surtout moins problÃĐmatique, est de se cantonner à lâexploitation ultÃĐrieure : imaginer par exemple modifier en direct la source de transformations XSL, et obtenir des rÃĐsultats (ou simplement parcourir le contenu grÃĒce à XPath). Sans avoir la source originale, des informations peuvent Être perdues et, plus grave, la structure initiale (son arborescence) de la page source est perdue.
La recrÃĐation dâun ÃĐlÃĐment dÃĐdiÃĐ dans la page gÃĐnÃĐrÃĐe nâapporte donc rien dans notre exemple, mais se rÃĐvÃĻle utile pour exploiter pleinement les conditions offertes par les WebExtensions.
II-D. CrÃĐer une page dâÃĐdition des transformations XSL▲
Je donne en fin de cette partie, le code source en deux parties dâune page dâÃĐdition des transformations XSL stockÃĐes. Je parle bien ici seulement des transformations, et pas dâune page pour ÃĐditer ÃĐgalement les rÃĻgles (cf le pattern matching).
La page en tant que telle nâoffre pas beaucoup dâintÃĐrÊt, sinon permettre dâÃĐditer les ÂŦ fichiers Âŧ (sources, en rÃĐalitÃĐ des simples chaÃŪnes de caractÃĻres) XSL qui servent aux transformations du HTML pour certaines URL interceptÃĐes.
Elle ne nous servira cependant de support quâen illustration de deux points :
- Un cas de script de page qui se comporte comme un script de contenu (quel contexte, quel intÃĐrÊt et pourquoi un tel comportement?) ;
- Lâutilisation de la balise template, une nouveautÃĐ fort utile pour la mise au gabarit issue de HTML5, que je citais plus haut.
II-D-1. La gabarisation en HTML5▲
Avant de rentrer dans notre sujet, comprenons notre contexte en dÃĐtail. Dans un script de contenu ou dâarriÃĻre-plan (ou par la console du dÃĐbug des WebExt, pas par la console dâune page!), testez le code suivant :
Function("console.log('ok');");
âĶ la rÃĐaction ne se fait pas attendre et lâÃĐvaluation de texte composant le corps de la fonction nâest pas exÃĐcutÃĐe. Ainsi Function est un ÂŦ ÃĐquivalent Âŧ (à gros traits) de la fonction eval â à cette diffÃĐrence que la premiÃĻre est une fonction qui en retourne une ÂŦ prÊte à lâemploi Âŧ et non une ÃĐvaluation destinÃĐe à une exÃĐcution immÃĐdiate. Vous devriez avoir le message suivant dans une console liÃĐe à la WebExt :
2.
3.
>> Function("console.log('ok');");
Error: call to Function() blocked by CSP debugger eval code:1:1
Content Security Policy: Les paramÃĻtres de la page ont empÊchÃĐ le chargement dâune ressource à self (ÂŦ script-src Âŧ). Source: call to eval() or related function blocked by CSP. debugger eval code:1:1
Dans un contexte de script de page, ou de la console dâune page ÂŦ classique Âŧ, le rÃĐsultat est bien une fonction anonyme :
Vous pouvez donc ÂŦ exÃĐcuter Âŧ cette fonction anonyme. Je vous invite à lire la documentation affÃĐrente (ainsi quâun chapitre en sus ici) et à tester en dehors de ce tutoriel ces notions avant dâaller plus loin.
Ce que vous devez garder à lâesprit, câest quâune des limitations â sinon la limitation majeure â, des WebExt est lâÃĐvaluation dâexpressions. Elle est strictement interdite en tout lieu(2). Ce comportement est une CSP â Content Security Policy (ici gÃĐrÃĐ par le navigateur lui-mÊme) â dont hÃĐrite par exemple le refus dâune requÊte cross-domain.
Pour faire simple : les rÃĻgles entre page Web et WebExt sont des inverses sur ces sujets. Le cross-domain est permis (avec les droits associÃĐs obtenus), mais lâÃĐvaluation ne lâest pas. La raison est ÃĐvidente : ÃĐviter quâun assaillant puisse exÃĐcuter en contexte dâarriÃĻre-plan ou de script de contenu, du code arbitraire. Y compris si ce code est une chaÃŪne ÂŦ en dur Âŧ dans votre script initial.
Or certains outils de mise au gabarit, dont la qualitÃĐ est inÃĐgale par ailleurs, souvent lourds pour peu dâopÃĐrations, peuvent Être amenÃĐs à utiliser lâÃĐvaluation dâexpressions de maniÃĻre lÃĐgitime. Aussi je vous dÃĐconseille fortement lâutilisation des bibliothÃĻques ÂŦ toutes prÊtes Âŧ qui ne sont pas spÃĐcifiquement conçues pour les WebExt. Dâabord leur rÃĐcupÃĐration par le navigateur imposerait dâexposer la WebExt à du code extÃĐrieur (avec des complications pour que leur contenu soit exÃĐcutÃĐ si cela passe par une requÊte!), ce qui est dÃĐjà en soi un risque, mais de plus les bibliothÃĻques peuvent provoquer des erreurs dues à la configuration particuliÃĻre de leur environnement.
Le mieux si vous souhaitez en utiliser, est leur intÃĐgration dans le projet en tant que tel (donc ÂŦ figer Âŧ la version utilisÃĐe) et en prenant un soin minutieux à connaÃŪtre leur fonctionnement interne.
La solution la plus simple est de passer par ce qui est offert par le navigateur et lâÃĐvolution de HTML. La version 5 prÃĐvoit ainsi une balise template qui agit dâune maniÃĻre similaire à ce que serait un DocumentFragment. La balise, qui est insÃĐrÃĐe dans dans le code source HTML, fait partie du DOM mais nâest pas prise en compte pour lâaffichage par le navigateur : il nây a donc aucun rendu (aucune rÃĻgle CSS ne devant lui-Être directement associÃĐe). Elle est appelable par les fonctions de sÃĐlection CSS cependant, ce qui lui permet dâÊtre utilisÃĐ indÃĐpendamment par .getElementByTag(Class)Name ou par .querySelector.
Son appel par JS retourne une entitÃĐ HTML un peu particuliÃĻre (comme la balise form retourne par exemple une liste accessible dâentrÃĐes, pouvant se comporter comme un tableau). Ici le contenu du gabarit est accessible par lâattribut .content de lâobjet template. Ce contenu peut Être modifiÃĐ et/ou clonÃĐ Ã volontÃĐ, par exemple pour reproduire un mÊme formulaire, un tableau, etc â ou mÊme un fil dâactualitÃĐ.
Lâusage, comme vous pourrez en avoir un aperçu dans la source que je donne pour lâÃĐditeur, est trÃĻs souple en plus de correspondre strictement aux spÃĐcifications du W3C.
Car, dernier point à garder à lâesprit, certaines pratiques â si elles sont toujours possibles â sont dÃĐconseillÃĐes pour les WebExt. Ainsi lâÃĐvaluation de HTML est possible quand lâÃĐvaluation JS ne lâest pas, mais la validation et la publication sur une plateforme â notamment celle de Mozilla â provoquera une alerte. A terme, cela pourrait Être rÃĐdhibitoire :
(Extrait) Warning: If your project is one that will undergo any form of security review, using innerHTML most likely will result in your code being rejected. For example, if you use innerHTML in a browser extension and submit the extension to addons.mozilla.org, it will not pass the automated review process.
Ainsi voici ce qui ne faut pas faire :
var p = document.createElement("p");
p.innerHTML = "<i>coucou</i>";Voici ce qui est souhaitable :
â soit prendre un gabarit template dans votre code source avec querySelector, et utiliser .textContent pour ajouter votre contenu texte. Vous pouvez ÃĐgalement utiliser la fonction DOMParser qui vous retournera un document utilisable ;
â soit crÃĐer de toute piÃĻce le paragraphe et le balisage italique en Javascript, avant dâinsÃĐrer le contenu là aussi avec .textContent.
Lâutilisation conjointe et intelligente de template et de MutationObserver permet dâoffrir à peu de frais un comportement similaire à une bibliothÃĻque de DOM virtuelle.
II-D-2. Un cas pratique et exotique de script de contenu▲
Dans notre fichier dâarriÃĻre-plan background.js, nous avons utilisÃĐ les ÃĐcouteurs dâÃĐvÃĐnements pour intercepter les requÊtes HTTP en fonction du type (main_frame pour notre cas) et de pattern matching, câest-à -dire dâune correspondance de motif des URL.
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
browser.webRequest.onBeforeRequest.addListener(
listener,
{
urls: browser.SurveilleURLs,
types: [
"main_frame"
]
},
[
"blocking"
]
);
Cet ÃĐcouteur renvoie en outre à une fonction listener crÃĐÃĐe de toute piÃĻce pour lâoccasion. Afin dâaccÃĐder à notre page dâÃĐdition, nous utiliserons le mÊme principe. à cette diffÃĐrence que nous allons ÃĐcouter le clic sur un bouton ajoutÃĐ Ã lâinterface du navigateur. Commençons par ajouter à notre fichier manifest le bloc suivant, avec un fichier de logo ÂŦ qui va bien Âŧ à la racine de notre WebExt :
2.
3.
4.
5.
6.
"browser_action": {
"default_icon": {
"19": "logo.png"
},
"default_title": "Editeur de transformations"
}
Magie : le bouton apparaÃŪt ! Il ne reste plus dans notre fichier dâarriÃĻre-plan quâà ajouter un ÃĐcouteur adaptÃĐ :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
18.
19.
20.
21.
22.
browser.browserAction.onClicked.addListener(
() => {
browser.tabs.create(
{
url: browser.extension.getURL(
"edition.html"
)
}
).then(
(objTab) => {
browser.tabs.executeScript(
objTab["id"],
{
"file" : browser.extension.getURL(
"edition.js"
)
}
);
}
);
}
);
DÃĐcomposons les deux ÃĐtapes de cette portion de code : ouvrir un nouvel onglet vers la page edition.html, puis une fois cet onglet crÃĐÃĐ, nous utilisons son ID sur le navigateur pour y injecter un script JS : edition.js.
Lâinsertion ÃĐtant faite lorsquâune page est appelÃĐe â câest-à -dire ici quâun onglet est ouvert â, le rechargement simple, avec F5 par exemple, nâappellera pas le script à nouveau. Celui-ci nâÃĐtant pas connu sur la page, celle-ci restera inerte. Je vous encourage vivement à tester le code plus haut, mÊme sâil ne remplit pas la fonction que lâon aurait pu initialement attendre. Ce cas se prÃĐsente ici compte tenu de la spÃĐcificitÃĐ de lâenvironnement (page interne à la WebExt).
Pour Être chargÃĐ Ã chaque chargement du document, le script de notre page dâÃĐdition doit Être appelÃĐ dans lâentÊte de la page dâÃĐdition et non pas dans le script dâarriÃĻre-planâĶ
<script type="text/javascript" src="./edition.js"></script>
Le script dâarriÃĻre-plan pour ce point, se limite dÃĐsormais à  :
2.
3.
4.
5.
6.
7.
8.
9.
10.
browser.browserAction.onClicked.addListener(
() => {
browser.tabs.create(
{
url: browser.extension.getURL(
"edition.html"
)
}
);
}
Nouveau problÃĻme me direz-vous ? Comme nous appelons notre script dans la page, quelle sera la portÃĐe des variables ? Aura-t-on accÃĻs à la partie de lâAPI WebExt dÃĐdiÃĐe au script de contenu ? HÃĐ bien oui : contre toute attente, câest lâURL, pointant sur lâID de la WebExt et sur un protocole ÂŦ propriÃĐtaire Âŧ (moz-extension), qui permettra au navigateur dâautoriser le script devenu script de page à se comporter comme un script de contenu.
Faites le test :
console.log("browser", browser);
âĶ renverra aussi bien lâobjet browser dans le script dâarriÃĻre-plan insÃĐrant un script de contenu, que dans le script de page se comportant comme un script de contenu.
Nous pouvons donc intelligemment penser notre code pour rÃĐutiliser un peu partout les mÊmes bibliothÃĻques de procÃĐdures et de fonctions. Cependant nous devons dÃĐsormais intercepter le chargement de la page : lâinsertion du script en tant que de notre script de contenu en tant que script de page, arrive antÃĐrieurement à ce quâaurait fait une insertion depuis lâarriÃĻre-plan de la WebExt.
Ainsi window.addEventListener sur lâÃĐvÃĐnÃĐment load peut devenir impÃĐratif si vous souhaitez contrÃīler le dÃĐclenchement de certaines fonctions aprÃĻs le chargement complet de la page (DOM et contenus extÃĐrieurs).
II-E. Les sources complÃĻtes de la page dâÃĐdition▲
II-E-1. La page▲
II-E-2. Le script de contenu▲
III. Seconde partie : ajouter un bouton dâaction à un rÃĐseau social▲
III-A. Le contexte▲
Jâindique ici la possibilitÃĐ dâajouter un bouton dâaction : cela peut Être aussi une surveillance de contenu, rÃĐcupÃĐrer ou copier des contenus, etc : la base â la surveillance dâune page, avec lâinjection dâun code â reste peu ou prou la mÊme.
Dans notre fichier background.js, nous ajoutons ces quelques lignes que vous connaissez dÃĐjà  :
2.
3.
4.
5.
browser.contentScripts.register({
"js": [{file: "/twitter.js"}],
"matches": ["https://twitter.com/"],
"runAt": "document_idle"
});
âĶ et crÃĐons un fichier twitter.js à la racine de notre WebExt. DÃĐsormais ce fichier est injectÃĐ dans toutes les pages qui correspondent à la racine du domaine Twitter.
Si vous dÃĐcortiquez les principaux ÃĐlÃĐments intÃĐressants de la page Accueil de Twitter, celle avec la timeline, vous noterez que finalement cette ÂŦ ligne du temps Âŧ est composÃĐe dâune liste et de quelques DIV : rien dâexceptionnel. Nous agirons sur le menu de chaque tweet, en ajoutant à la fin un bouton qui, une fois cliquÃĐ, affiche un message.
â Pour la liste des tweets, voici un extrait des principaux ÃĐlÃĐments HTML intÃĐressants :
div#timeline > div.stream > ol#stream-items-id > li.stream-item > div.tweet
â Pour le menu de chaque tweet :
div.dropdown-menu > ul (role=menu) > li.copy-link-to-tweet > button.dropdown-link
III-B. Le principe▲
Twitter, comme Facebook ou Google, et dâautres, gÃĐnÃĻre en quelque sorte une page avec trÃĻs peu de donnÃĐes envoyÃĐes directement par le code source HTML de la page (que ce soit du HTML ou du JSON). Le gros du contenu est rÃĐcupÃĐrÃĐ ensuite, par des requÊtes (WS, ajout de scripts par le DOM ou Ajax, peu nous importe). Compte tenu du principe commun quâil sâagit dâun fil mis à jour en continu, intercepter chaque requÊte est lourd et il nây a ÃĐvidemment pas de documentation sur le fonctionnement interne des outils. Ces sites utilisent gÃĐnÃĐralement des requÊtes imbitiques : ne tentons pas de les comprendre !
Comme nous injectons un fichier JS et que nâavons pas les variables des scripts de la page, ce serait de toute façon bien trop compliquÃĐ Ã faire, il existe un moyen simple et probablement un des outils les plus puissants de JS pour le Web : MutationObserver.
Il sâagit dâun ÂŦ poste Âŧ dâobservation tel que peut le faire les evenement listener. à chaque ÃĐvÃĐnement dÃĐterminÃĐ arbitrairement, un callback est appelÃĐ par le navigateur avec en argument, un objet utile. Un MutationObserver peut Être activÃĐ et dÃĐsactivÃĐ.
Dans notre fichier twitter.js, ajoutons le code suivant :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
18.
19.
20.
function Agir(objR) {
console.log(objR);
}
var observateur = new MutationObserver(
(elsListe) => {
Agir(
elsListe[0].addedNodes
);
}
);
observateur.observe(
document.querySelector(
"ol#stream-items-id"
),
{
childList: true // on surveille seulement les ÃĐlÃĐments HTML enfants ajoutÃĐs
}
);
â Votre console de page devrait afficher un rÃĐsultat avec un tableau. Le premier item est le rÃĐsultat en tant que tel, le second item est lâobjet observÃĐ. Le premier item est un objet dont lâun des attributs, addedNodes, est la liste des enfants ajoutÃĐs à lâÃĐlÃĐment ol#stream-items-id. Câest-à -dire la liste des tweets de la timeline de la page.
à chaque fois que vous allez cliquer sur ÂŦ Voir (n) nouveaux tweets Âŧ, votre observateur dÃĐclenchera le callback Agir qui sera la fonction pour ajouter notre prochain bouton de menu. Reste que les tweets dÃĐjà ajoutÃĐs lors de la construction de la page ne seront pas traitÃĐs : nous devrons donc, dÃĻs le chargement de notre script de contenu twitter.js, les prendre en compteâĶ
Vous aurez compris le principe : on laisse la page se charger et agir ÂŦ normalement Âŧ, et on ne fait que surveiller puis intercepter les ÃĐlÃĐments qui nous intÃĐressent.
Le fichier twitter.js permettant lâajout dâun bouton dans le menu de chaque tweet, vous trouvez le code en fin de cette seconde partie. Il se passe de commentaires particuliers : aucune difficultÃĐ nâest à noter et les scripts de Twitter ne peuvent ni savoir (sauf sâils surveillent eux-mÊme les modifications effectuÃĐes) ni agir sur notre script de contenu.
Ce type de dispositif est ce que lâon retrouve entre Avast et Gmail par le navigateur, oÃđ lâutilisateur ne voit pas â lors de lâÃĐdition â quâAvast ajoute une signature sans le prÃĐvenir directement dans le code HTML des courriels envoyÃĐs par Gmail.
Une pub gratuite car le destinataire voit la signature et se sent faussement protÃĐgÃĐ. Ce comportement, inacceptable, est aussi un des mondes offerts par les WebExtension : jâimagine que mon propos liminaire sur la mise en garde prend son sensâĶ
III-C. Bonus : et si on affichait plutÃīt une notification ?▲
PlutÃīt que la classique ÂŦ alerte Âŧ JS qui impose dâÊtre sur le navigateur et sur la page appelÃĐe, une notification gÃĐrÃĐe par le navigateur dans le contexte de lâOS est parfois plus intÃĐressante (agenda, alerte hors du contexte de navigation, etc).
Modifions tout dâabord notre fichier manifest pour rajouter la permission des notifications :
2.
3.
4.
5.
6.
7.
8.
"permissions": [
"unlimitedStorage",
"storage",
"webRequest",
"notifications",
"webRequestBlocking",
"<all_urls>"
],
Puis ajoutons les quelques lignes suivantes au script dâarriÃĻre-plan background.js :
2.
3.
4.
5.
6.
browser.notifications.create({
"type": "basic",
"iconUrl": browser.extension.getURL("logo.png"),
"title": "Clic",
"message": "Je viens de Twitter !"
});
âĶ magie, dÃĻs le rechargement (automatique ou non) de votre WebExt, une notification apparaÃŪt ! Et le plus tragique : câest ce que ce beau code ne fonctionne pas en script de contenuâĶ Votre navigateur vous informera simplement que ÂŦ browser.notifications is not defined Âŧ. Câest logique : votre API en contexte script de contenu est davantage limitÃĐ que celle offerte au script dâarriÃĻre-plan, pour ÃĐviter un abus gÃĐnÃĐrÃĐ par la page.
Modifions notre fonction BoutonAlerte par le code suivant :
Jâutilise ici la mÃĐthode runtime de lâobjet browser qui permet de transmettre des objets entre les diffÃĐrentes zones / contextes dâexÃĐcution des scripts de la WebExt. DÃĻs lors il ne reste plus quâà crÃĐer lâÃĐcouteur dâÃĐvÃĐnement et savoir si le message associÃĐ est bien une demande de notification :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
browser.runtime.onMessage.addListener(
(objMessage) => {
if (
"type" in objMessage
&
objMessage["type"] == "notification"
)
browser.notifications.create({
"type": "basic",
"iconUrl": browser.extension.getURL("logo.png"),
"title": objMessage["titre"],
"message": objMessage["message"]
});
}
);
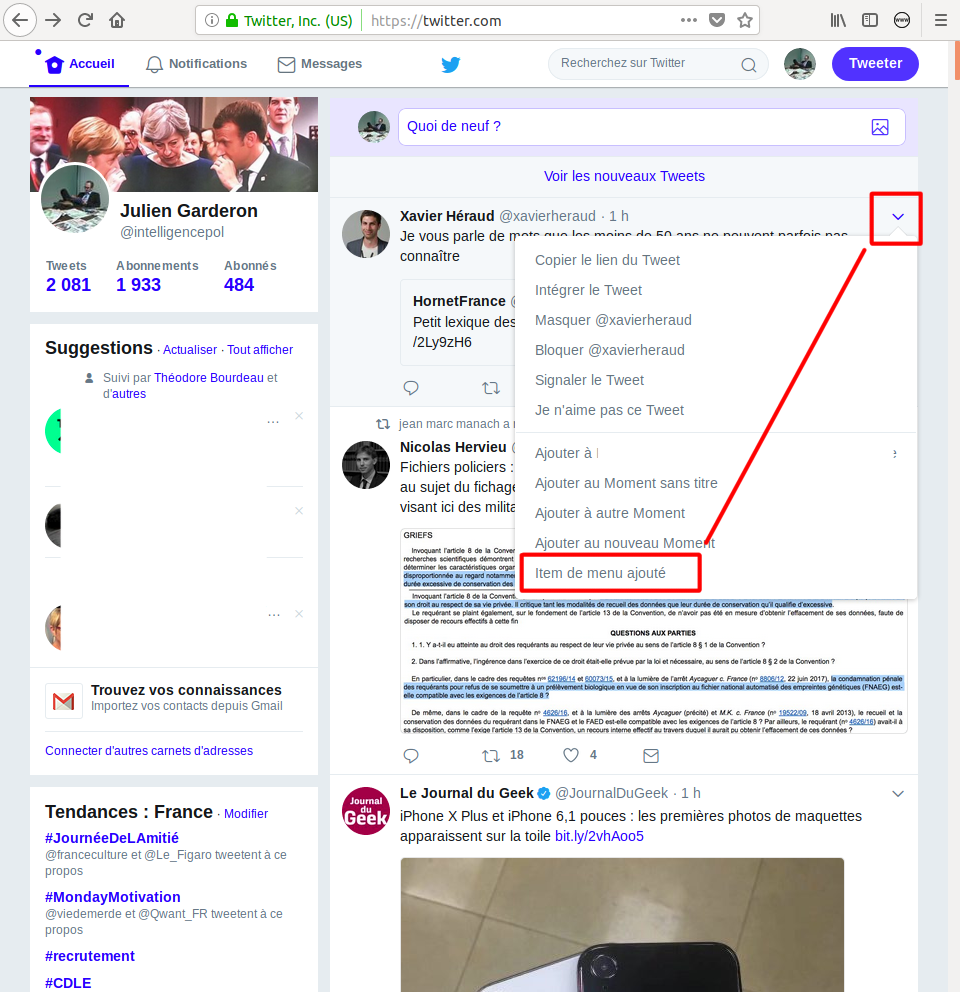
Et là miracle : le clic sur le menu dâun tweet provoque lâapparition dâune notification ! Je vous laisse imaginer lâoutil puissant de suivi des rÃĐseaux sociaux que vous pouvez ainsi construire ainsi, assez facilement.
Voici votre item de menu pour chaque tweet tel quâil devrait apparaÃŪtre :
III-D. Le code source complet du script twitter.js▲
IV. Conclusion, ouverture et remerciements▲
Ce tutoriel a balayÃĐ de nombreux concepts et outils, intÃĐgrÃĐs à diffÃĐrents niveaux dans les navigateurs. Si les WebExtensions comme les transformations du XML sont bien gÃĐrÃĐes par les ÂŦ poids lourds Âŧ du secteur, des nuances peuvent encore exister dans lâexploitation des API. Ainsi les WebExtension ne signent pas la fin du travail dâajustements entre navigateurs, mais une premiÃĻre ÃĐtape fondamentale à lâharmonisation.
Jâai abordÃĐ ici le seul point du contenu, du corps, des requÊtes. Lâassociation des WebExtensions avec toutes les possibilitÃĐs (interception et ÃĐmission de requÊtes, modification dâentÊtes, proxy ÂŦ complet Âŧ, palliatif aux restrictions cross-domain, etc), les API pour dialoguer avec les autres logiciels du poste, le code machine à la sauce WebAssembly, ainsi quâun contexte dÃĐsormais multi-thread, tout cela permet à un navigateur dÃĐjà ÂŦ lourd Âŧ de devenir ÂŦ colossal Âŧ â pouvant remplaçant ou gÃĐrer la quasi-totalitÃĐ de nos tÃĒches quotidiennes.
Un aperçu de la compatibilitÃĐ des API exhaustives, entre les principaux navigateurs, nous illustre ce poids considÃĐrable que peut prendre un navigateur.
Probablement à terme, malgrÃĐ la rÃĐticence des majors de services en ligne, irons-nous vers des applications bien plus ÂŦ ouvertes Âŧ (au moins parce que le code nâest pas compilÃĐ!) et non-propriÃĐtaires : Firefox est par exemple accessible sous les OS, mobiles y compris (à lâexclusion dâApple, dont iOS impose un moteur). Or lâintÃĐrÊt dâune WebExtension pour un service en ligne, câest de cibler la quasi-totalitÃĐ des OS, fixes et mobiles, ainsi que les principaux navigateurs mobiles.
Ne faut-il pas dÃĐjà rÃĐflÃĐchir à abandonner une part des applications mobiles et des ÃĐcosystÃĻmes parfois fermÃĐs de diffusion (Apps Android / Google Store, Apple Store, Windows Store, etc.) ?
La question mÃĐrite dâÊtre posÃĐe et dâÊtre posÃĐe rapidement.
IV-A. De la question des droits et des usages▲
DerriÃĻre toutes ces opportunitÃĐs, se cache encore et toujours lâÃĐducation de lâutilisateur : je nâai illustrÃĐ ici quâune infime partie de ce quâil est possible de faire. Les bloqueurs de pub et les ÂŦ anonymiseurs Âŧ, rentrent naturellement dans la catÃĐgorie des ÂŦ bons Âŧ usages de ces droits ÃĐtendus sur le surf de lâutilisateur. Mais nous serions pour le moindre crÃĐdules, de croire que ces usages restent pacifiques. Comme pour Android, ou iOS, les dÃĐveloppeurs risquent dâÊtre tentÃĐs de demander ÂŦ toujours plus Âŧ de droit pour les WebExtensions, alors que ces droits sont finalement trÃĻs peu ÂŦ lisibles Âŧ pour un utilisateur lambda, et peuvent lui crÃĐer de sÃĐrieux dommages sur le respect de sa vie privÃĐe et des considÃĐrations techniques sur la sÃĐcuritÃĐ et la fiabilitÃĐ de ses machines.
De plus la question des droits rejoint celle des usages : or un navigateur est souvent ÂŦ connectÃĐ Âŧ à dâautres, par le biais dâun profil qui permet à lâutilisateur dâÊtre itinÃĐrant dans sa logique dâutilisateur du Web, jonglant entre les pÃĐriphÃĐriques (mobiles ou fixes). Les effets peuvent Être en cascade, alors que lâattente est diffÃĐrente. Les puissances, lâespace de stockage et la gestion mÊme des ressources : sur Android par exemple, il nâest pas rare de voir lâOS ÂŦ dÃĐcharger Âŧ de la RAM un logiciel, puis le reprendre. Si vous avez une WebExt dâagenda, vous pourriez ne pas remplir pleinement la fonction si votre navigateur nâest pas rÃĐguliÃĻrement ouvert et ce dernier sera prÃĐcautionneux quant au temps de calcul et à la frÃĐquence du dÃĐclenement de certains ÃĐvÃĐnements pris par vos scripts.
IV-B. Les WebExtensions sont-elle finalement la pierre angulaire du Web dÃĐcentralisÃĐÂ ?▲
Avec lâÃĐmergence et une nouvelle cohÃĐrence dans la socialisation du Web, dont lâÃĐclatement en ÂŦ fÃĐdÃĐrations Âŧ et ÂŦ services Âŧ impose de nouvelles approches à taille humaine, les WebExtensions pourraient devenir une clÃĐ de voÃŧte de systÃĻmes nouveaux mais aussi de risques nouveaux : comme je lâindiquais dans les recommandations en introduction, la sÃĐcuritÃĐ des extensions est loin dâÊtre parfaite malgrÃĐ les limitations des API. DerriÃĻre, câest la sÃĐcuritÃĐ dâun logiciel, le navigateur, qui est impactÃĐe et donc la sÃŧretÃĐ de lâensemble de la machine.
Reste dâautres limites â sur la garantie des donnÃĐes stockÃĐes, qui nâest aujourdâhui logiciellement pas assurÃĐe â, comme lâintÃĐrÊt dâÃĐtendre certaines API (faut-il par exemple, permettre à un navigateur de se comporter comme un serveur, à la mode NodeJS ?). Car crÃĐer un navigateur ÂŦ qui fait tout Âŧ, câest aussi (un peu) remplacer progressivement lâintÃĐrÊt dâun OS et de la richesse de ses logiciels, en rendant lâutilisateur dÃĐpendant dâune plateforme qui nâoffre tout de mÊme pas les garanties et le suivi que peuvent avoir la plupart des OS aujourdâhui. Il est donc, au-delà de la partie sÃŧretÃĐ / sÃĐcuritÃĐ, question de stabilitÃĐ et dâintÃĐrÊts.
ChromeOS avait en partie rÃĐpondu à cette question dÃĻs 2011, suivi par Ubuntu Touch qui nâa pas trouvÃĐ son public de ÂŦ partenaires Âŧ., Les WebExtensions ne sont pas ÃĐloignÃĐes de lâintÃĐrÊt des conclusions sur ces OS prÃĐcurseurs quant aux coÃŧts rÃĐduits des machines, et dont la puissance est dÃĐportÃĐe sur le rÃĐseau vers les fermes de serveurs. La trÃĻs faible configuration nÃĐcessaire est permise aussi compte tenu dâune interface exclusivement orientÃĐe vers le HTML5/Web.
Vraiment un autre monde mais finalement pas si ÃĐloignÃĐ des anciensâĶ
V. Note de la rÃĐdaction de Developpez.com▲
Nous tenons à remercier ALT pour la relecture orthographique de ce tutoriel.