



I. Introduction▲
Très souvent, la programmation « classique », « ligne à ligne » (séquentielle), trouve ses limites lorsqu'elle doit faire au moins deux tâches en parallèle (c'est-à-dire dans un même temps) : gérer plusieurs clients pour un serveur, définir une multitude d'états en simultané, lire et comprendre tel et tel fichier… Le plus simple est d'attendre. Le script se comporte alors ainsi : je termine, puis je passe au reste.
Problème, c'est parfois trop tard : le client est parti, la connexion est rompue, la donnée est perdue. Ou, plus simplement, du temps, une valeur cardinale en informatique, est perdu et avec lui de l'énergie est consommée (et gaspillée).
Ce comportement « une tâche à la fois » semble pourtant différent du fonctionnement « classique » d'un processeur monocœur. Ce n'est pas le cas : il « découpe » son temps de calcul en une fraction minime qu'il répartit sur tous les besoins logiciels. Nous, humains, avons l'impression que notre processeur fait plusieurs tâches en même temps. Ce qui est vrai si l'on considère une durée « longue » pour la machine (une seconde ou une minute). Techniquement, ce même processeur n'exécute pourtant qu'un seul programme par cœur de traitement à un moment donné.
Cette notion de « cœur » est importante, car elle est désormais au centre de l'attention des constructeurs : face au défi technique de plus en plus grand du duo miniaturisation/performance, il est plus simple de multiplier les cœurs de calculs que d'augmenter la fréquence. Les inconvénients sont plus limités et gérables…
Chaque cœur, à un instant donné, calculera pour un processus - les processeurs multicœurs peuvent donc gérer réellement plusieurs processus dans un même instant.
C'est cette notion entre la réalité (ou non) d'un calcul unique ou de calculs parallèles que nous aborderons de cet article. L'écriture synchrone d'un programme (sur un seul processus, c'est-à-dire une seule « entité » logicielle) va être transformée pour devenir une forme de gestionnaire de calculs au travers de fonctions (de morceaux de cette « entité » logicielle). Nous serons toujours sur un seul processus, mais celui-ci se rapprochera en comportement des processeurs monocœurs des origines de l'informatique : faire extrêmement vite un petit calcul pour une tâche et passer à la suivante - en donnant ainsi l'illusion que des tâches sont réalisées simultanément, en parallèle.
I-A. « Temps, suspends ton vol »▲
Pour en revenir à notre problème d'avoir plusieurs tâches à gérer en même temps, nous avons aujourd'hui et historiquement, deux grandes familles qui « s'affrontent » - disposant chacune de grandes forces et faiblesses :
- les threads : du calculconcurrentiel (car sur un seul processus) qui, en résumé, « subdivise » le temps disponible de calcul du processeur pour un programme, en une multitude d'autres temps pour des calculs en interne du programme. La mémoire et le temps de calcul sont « partagés ». Les threads sont faciles conceptuellement, mais offrent certaines limites : ils n'utilisent qu'un seul cœur de processeur qui est donc surutilisé (la pratique est parfois différente suivant les architectures) et il est nécessaire de consommer beaucoup de ressources pour gérer les threads - avec une limite (GIL) évoquée plus loin. La gestion des ressources est parfois délicate (par exemple, une base SQLitle), car chaque thread ne s'occupe pas de ses frères et il est nécessaire d'utiliser des « verrous » (locks) pour éviter des accès simultanés et mortifères.
Les threads disposent d'un module dédié et natif dans la bibliothèque standard de Python. - les multiprocess : du calcul parallèle (car sur plusieurs processus) qui utilisent utilement les nombreux cœurs dont disposent désormais nos processeurs. Le principe est de déléguer à un nouveau processus Python (multiprocessing, fork) ou à un appel système différent (subprocess), une part du travail de manière indépendante en termes de calcul, du processus parent. Cependant la mise en œuvre est complexe : il faut les faire dialoguer entre eux, et le code, parfois pour quelques lignes de calculs, peut alors devenir indigeste. La séparation des processus ne résout pas nécessairement les problèmes de concurrence lors de l'accès aux ressources : les verrous restent nécessaires… de plus il n'y a pas des variables communes : il est nécessaire d'avoir un niveau d'abstraction supplémentaire pour faire dialoguer en temps réel, le partage d'une variable ou de son édition.
Finalement dans tout cela, ce que l'on veut tous faire, tout le temps, c'est dire à la machine : plutôt qu'attendre, fais autre chose. Puis reviens reprendre ton travail lorsqu'on t'en donne le signal ou qu'une ressource est disponible.
Face à ce défi et à l'évolution (positive) des pratiques, une nouvelle organisation de l'écriture séquentielle a vu le jour : offrir la souplesse des threads sans le problème de chaos et certaines limitations natives ; ou partir sur une nouvelle manière de créer un autre processus - donc en restant restreint à un seul cœur de processeur… Cette évolution c'est l'asynchrone ou quand le séquentiel ne se comporte plus tout à fait comme il l'a toujours fait jusqu'à présent. Mais le mode asynchrone n'est ni un « nouveau » thread, ni un nouveau processus dans le programme. C'est autre chose, qui n'est pas une troisième voie, mais une autre voie.
La nouveauté offerte par le mode asynchrone et sa puissance réelle par certains aspects, a fait naître la « mode » de l'asynchronisme à tous les étages, le don de faire une multitude de choses « en parallèle »… et son cortège d'illusions : il n'y a en réalité qu'une seule et unique tâche à un instant t. C'est bien la vitesse qui simule le parallélisme.
Cette mode, parfois déraisonnable, est notamment portée grâce au web par JavaScript type Node.JS ou le logiciel nginx, qui pulvérisent effectivement tous deux les performances d'Apache et son approche très classique…
Pour une partie de la communauté des développeurs, l'asynchronisme c'est devenu, c'était donc (et c'est encore) un truc dédié pour le web, pour le réseau ou pour l'accès à l'interface E/S des fichiers ; pas pour le calcul pur ou une conception plus « classique » du logiciel. Sans être faux, ce raisonnement est limité, car c'est en réalité une conception différente de l'utilisation du temps processeur, des accès fichiers et des ressources RAM… Faisons le point sur les mérites et les failles avec méthode et objectivité.
I-B. L'asynchronisme n'est pas la panacée du développement▲
Je vais doucher vos espoirs tout de suite : votre serveur saupoudré d'asynchronisme ne sera pas plus performant dans l'absolu, vous passerez juste moins de temps à attendre (et donc vous en profitez pour en faire plus, mais sans dépasser la possibilité totale native de calcul du système). La démonstration de ce qu'est et n'est pas l'asynchronisme est l'objet de ce tutoriel, en plus de vous le faire découvrir.
Vous y gagnerez une forme de parallélisme des tâches certes. Ce parallélisme permet de répondre à davantage de sollicitations, mais le cœur même du calcul de votre script - au travers de vos fonctions - restera présent et n'en sera pas modifié. Et le temps de réponse d'une ressource aussi. Par exemple : votre requête mal ficelée en MySQL qui prend trois secondes à s'exécuter avant de vous retourner le résultat, multiplié par des milliers d'utilisateurs en simultané, ne s'arrangera pas. La requête fera toujours trois secondes et s'il n'y a pas d'autres tâches à réaliser en attendant (cas d'école !), votre script tournera tout autant dans le vide qu'avant.
Pire, sur le calcul pur, les threads sont plus simples et plus performants ; moins que ce peut être le multiprocessing sur un processeur multicœur, qui explosera l'efficacité de l'asynchronisme sans l'ombre d'un doute. À chaque usage les performances de ces solutions varient.
Avant de revenir à ces conclusions, il vous faudra un long, très long parcours aux confins du langage si délicieux de Python… Même si vous n'êtes pas un habile programmeur, c'est à la portée de tous. Encore faut-il bien en comprendre les ressorts pour ne pas en perdre le sel...
II. Aux sources▲
II-A. Aux origines : les itérateurs et le mot-clé yield ▲
Le mot-clé yield n'est pas une particularité de Python : on le retrouve historiquement dans le C ou dans JavaScript, comme l'illustre l'article associé sur MDN. Malgré sa notoriété finalement assez faible - peu de tutoriels l'évoquent lors de l'initiation à la programmation -, sa puissance le rend incontournable lors d'une programmation poussée et professionnelle.
C'est un mot-clé un peu particulier, qui se rapproche de with ou encore l'opérateur @ pour les décorateurs : il est une sorte de « raccourci » qui renferme la complexité et retourne un objet qui est différent de celui-ci initialement fourni (fonction X → objet G). yield a une particularité : il ne fonctionne QUE dans les fonctions (ou les fonctions des objets, que l'on appelle communément les méthodes, avec lesquelles il travaille sans problème). Il retourne systématiquement un objet (une classe instanciée) de type « generator » (générateur). L'asynchronisme appelle ce générateur différemment, nous y reviendrons en fin de cet article ; son nom véritable n'a que peu d'importance pour l'instant.
Jusque-là c'est facile ? Oui mais, il y a une nuance… un générateur se comporte avant tout comme un « itérateur » que l'on retrouve partout dans Python ! Rappelons tout d'abord ce qu'est un itérable : il s'agit d'un objet qui garde en mémoire d'une manière finie (range(0,9), par exemple) ou infinie (le retour d'un calcul dans une boucle while True), une série d'autres objets/une valeur lorsqu'on l'itère (l'itérable a donc besoin d'être itéré par un itérateur, un iterator). De nombreux exemples des itérables et de leur intérêt sont déjà fournis sur le site (voir à ce sujet l'article d'Alexandre Galode pour les propriétés). Un itérateur renvoie donc une valeur à chaque passage/appel et il permet de contrôler ces passages de manière fine.
Un generator est un itérable (en somme il se parcourt lui-même) - et l'inverse, pour les itérateurs, n'est pas loin d'être vrai : un itérateur est, dans le code Python, à rapprocher d'un generator par certaines méthodes - même si leur ressemblance s'arrête là. Cependant et comme nous le verrons plus loin, les concepts d'itération, de machines à états, d'asynchronisme ou de call-back, forment une masse où il est parfois difficile de définir des cas d'utilisation tout à fait clairs. Pour respecter les règles de l'écriture « pythonique » et les orientations de chaque sensibilité du développement, la communauté a ainsi créé de nouveaux mots-clés (dont yield from et async/await) qui tentent d'éclaircir l'orientation du développement. Reste derrière cela, qu'il s'agit toujours d'un fonctionnement similaire (découper en portion individuelle « à la volée ») avec des subtilités qu'il faut connaître.
Dans le détail, les « iterators type » sont des objets (des containers, des boîtes en somme), qui permettent de renvoyer une valeur unique à chaque appel (grâce à la méthode __next__₎. Lors de la création (par exemple, lors d'un appel dans une boucle for), c'est le même nom __iter__ qui est utilisé pour renvoyer l'itérateur depuis la classe de départ, puis une valeur. Pour yield, la méthode __iter__ n'est disponible que lorsque la fonction de départ a été appelée une première fois ; sinon elle est référencée et se comporte comme une fonction normale. Il y a donc une « transformation » de l'appel de la fonction en autre chose (voir plus haut la transformation fonction X → objet G).
Les fonctions __iter__ et __next__ sont ensuite disponibles pour les generators. Nous pourrons donc utiliser dans nos boucles for des générateurs ou des itérateurs indifféremment. Pratique !
En voici la démonstration :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
>>> def test():
yield
>>> type(test())
<class 'generator'>
>>> test().__iter__ # on demande __iter__ sur une fonction appelé
<method-wrapper '__iter__' of generator object at 0xb5b4220c>
>>> test.__iter__ # on demande __iter__ sur une variable contenant la fonction non-appelée
Traceback (most recent call last):
File "<pyshell#10>", line 1, in <module>
test.__iter__
AttributeError: 'function' object has no attribute '__iter__'
>>> test().__next__
<method-wrapper '__next__' of generator object at 0xb5b42a4c>
Un itérateur peut donc être « caché » dans une fonction appelée - en quelque sorte « encapsulé » dans un container, avant d'être disponible. Et l'itérable est le generator ; les deux étant liés grâce, par exemple, à un décorateur (comme vous pouvez le lire un peu partout avec @asyncio.coroutine).
II-B. Itérable, iterator, generator… je suis déjà perdu ! ▲
Normal c'est l'enjeu même du tutoriel et nous n'en sommes qu'au début. Ce qu'il faut comprendre, et retenir, c'est la philosophie Python : tout est objet et ainsi, pour avoir des comportements les plus génériques possible, on utilise des méthodes d'objets avec des noms similaires pour un même contexte. Peu importe votre point de départ, c'est l'objet qui est généré à l'arrivée et rendu qui comptera : c'est ainsi que cela fonctionne dans Python, où par exemple la fonction (définie par défaut) iter() prend un itérable en entrée et lui « ajoute » le générateur synchrone nécessaire pour le parcourir facilement.
Il s'agit, dans notre cas, du protocol iterator - du protocole d'itération -, la manière dont Python fera appel à des objets grâce à des méthodes aux noms génériques.
Tentons pour rendre cela plus concret, de simuler une boucle for qui affichera les lettres contenues dans une liste (une liste = un itérable).
Voici le comportement normal et attendu :
Voici comment nous pourrions faire pour éviter d'utiliser totalement les listes en reproduisant le même résultat, en gardant à l'esprit que j'ai ajouté des commentaires :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
18.
19.
20.
21.
22.
23.
24.
25.
26.
27.
28.
29.
30.
31.
32.
33.
34.
35.
36.
37.
38.
39.
class MonPremierIterable():
def __init__(self, v1, v2, v3):
print("itérable : on fait appel à bibi ?")
self.v1, self.v2, self.v3 = v1, v2, v3
self.i = 1
def __next__(self):
print("itérable : j'en suis à :", self.i)
if self.i==1:
self.i += 1
return self.v1
elif self.i==2:
self.i += 1
return self.v2
elif self.i==3:
self.i += 1
return self.v3
else:
print("itérable : j'ai fini")
raise StopIteration("je retourne la valeur que je veux, nah")
class MaPremiereListe:
def __init__(self, v1, v2, v3):
print("simili-liste : je débute ma création")
self.v1, self.v2, self.v3 = v1, v2, v3
def __iter__(self):
print("simili-list : __iter__ est appelé")
return MonPremierIterable(
self.v1,
self.v2,
self.v3
)
for lettre in MaPremiereListe("a","b","c"):
print("-", lettre)
… donnera :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
simili-liste : je débute ma création
simili-list : __iter__ est appelé
itérable : on fait appel à bibi ?
itérable : j'en suis à : 1
- a
itérable : j'en suis à : 2
- b
itérable : j'en suis à : 3
- c
itérable : j'en suis à : 4
itérable : j'ai fini
En résumé :
- un itérable est un objet qui a des propriétés pour garder des éléments/des valeurs. Il peut « produire » un
iterator
sans que cela soit impératif (tout dépend du contexte, dont une partie est définie par le protocole standard associé) ;
- un
iterator
est un itérable avec la méthode
__next__
qui lui permet de parcourir des éléments/des valeurs (ce parcours est choisi arbitrairement : filtre, tri, pas, etc.) ;
- le protocole d'itération donnera pour consigne de lever une exception (le mot-clé
raise
) de type
StopIteration
(donc une exception d'un type particulier) qui dispose pour paramètre d'une seule valeur telle que pourrait le faire
return
. La boucle
for
n'affichera pas l'erreur, mais la gérera et ne fera rien (pour l'instant) de la valeur de l'exception - nous verrons bientôt son intérêt…
II-C. Et mes generateurs dans tout ça ?▲
Un générateur produit par un fonction qui contient yield, va parcourir chaque portion de code du début jusqu'au prochain
yield
(ou de
yield
en
yield
), tel que peut le faire un
iterator
. En somme, c'est un
iterator
qui utilise du code Python comme itérable…
Pour reprendre l'exemple de ma liste au-dessus, l'utilisation d'un générateur donnerait le code suivant :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
def generateur(v1, v2, v3):
yield v1
yield v2
yield v3
class MaPremiereListe:
def __init__(self, v1, v2, v3):
print("simili-liste : je débute ma création")
self.v1, self.v2, self.v3 = v1, v2, v3
def __iter__(self):
return generateur(self.v1, self.v2, self.v3)
for lettre in MaPremiereListe("a","b","c"):
print("-", lettre)
En plus court :
2.
3.
4.
5.
6.
7.
def MaPremiereListe(v1, v2, v3):
yield v1
yield v2
yield v3
for lettre in MaPremiereListe("a","b","c"):
print("-", lettre)
Pour illustrer qu'il n'y a bien qu'une portion de code exécutée, mettons un grain de sable :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
GrainDeSable = 0
def MaPremiereListe(v1, v2, v3):
global GrainDeSable
print("je fais quelque chose ...")
GrainDeSable +=1
yield v1
print("... j'continue, toussa toussa ...")
yield v2
print("allez j'me lance :", GrainDeSable)
print("et j'arrête avant la fin en provoquant une erreur \
qui ne soit pas une StopIteration")
raise Exception("on arrête")
yield v3
for lettre in MaPremiereListe("a","b","c"):
print("-", lettre)
… donnera :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
je fais quelque chose ...
- a
... j'continue, toussa toussa ...
- b
allez j'me lance : 1
et j'arrête avant la fin en provoquant une erreur qui ne soit pas une StopIteration
Traceback (most recent call last):
File "/home/julien/Bureau/tuto async/ref-5.py", line 16, in <module>
for lettre in MaPremiereListe("a","b","c"):
File "/home/julien/Bureau/tuto async/ref-5.py", line 13, in MaPremiereListe
raise Exception("on arrête")
Exception: on arrête
Vous devinez la suite : on détournera la fonction d'itération afin de disposer d'une sorte de «
fonction en mode pause
» à la demande où la méthode
__next__
du
generator
permet de reprendre temporairement la poursuite jusqu'au prochain
yield
ou en levant une exception
StopIteration
si la fonction se termine. Et le paramètre unique de
StopIteration
est… la valeur de retour de cette fonction.
Cette gestion
try/except
permet de renvoyer des valeurs
None
(
null
) sans problème particulier et d'en gérer plus finement l'usage, notamment en permettant au code qui gère le
generator
de détecter comment et quand se termine la fonction : normalement avec un StopIteration ou anormalement avec
toutes
les autres formes d'exception.
Par convention :
- on préférera toujours utiliser une boucle
while True
associée à
next()
, pour ne pas se poser la question du nombre d'itérations : l'itérable peut être infini et la boucle s'arrête par le déclenchement d'une exception de
StopIteration
;
- on utilisera la fonction native
next()
qu'appelle la méthode
__next__
du générateur. Ainsi
next(g)
et
g.__next__()
sont
strictement
équivalents.
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
def MaFonction(valeur):
i = 2
valeur = int(valeur)
i = valeur
yield
i = (valeur valeur)
return i
try:
generateur = MaFonction(3)
while True:
next(generateur)
except StopIteration as retour:
print(retour.value) # soit (2 x 3) x (3 x 3) ou 54
II-D. Des yield dans des yield… ▲
Parfois on a des générateurs dans les générateurs… Il faut alors gérer la question des exceptions StopIteration à tous les niveaux - c'est pénible et hasardeux, car si l'on en oublie un, telle une bulle, l'exception StopIteration levée et non interceptée, remontera au générateur au-dessus qui s'arrêtera - ce qui n'est pas du tout le comportement attendu.
Pour cela, Python a aussi une solution simplifiant l'écriture et évitant les erreurs de logique programmatique : yield from. C'est la même chose qu'un yield, mais en prenant une autre fonction qui retourne un générateur.
Voyons ce que ça donne pour afficher l'alphabet :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
18.
19.
20.
21.
22.
23.
24.
25.
26.
27.
28.
29.
30.
31.
32.
33.
34.
35.
36.
37.
def LettreGI():
print("g")
yield
print("h")
yield
print("i")
return "coucou"
def LettreDI():
print("d")
yield
print("e")
yield
print("f")
r = yield from LettreGI()
return r
def LettreAC():
print("a")
yield
print("b")
yield
print("c")
def Afficher():
r = yield from LettreAC()
print("! r = ", r)
r = yield from LettreDI()
print("! r = ", r)
return "bonjour"
try:
generateur = Afficher()
while True:
next(generateur)
except StopIteration as retour:
print(retour.value)
… donnera :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
a
b
c
! r = None
d
e
f
g
h
i
! r = coucou
bonjour
II-E. Yield : ce qui rentre… et ce qui sort ▲
Les lecteurs attentifs auront peut-être déjà remarqué que
yield
, comme
yield from
, pouvait prendre ou non une valeur comme « paramètre » (valeur située à droite) et en retourner une (valeur située à gauche). C'est optionnel et c'est la puissance des
generators
: permettre non seulement de mettre une fonction en pause, mais en plus pouvoir communiquer avec elle au moment de la pause (en entrée et en sortie de pause).
Mieux : le
yield from
permet d'être « transparent » et de donner complètement la main au générateur contenu dans un autre générateur.
Sur l'exemple de mon alphabet précédemment, je pourrais donc écrire :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
def Afficher():
while True:
lettre = yield
if lettre is None:
return "bonjour"
else:
print(lettre)
try:
alphabet = ["a","b","c","d","e","f","g","h","i"]
generateur = Afficher()
for lettre in alphabet:
generateur.send(lettre)
except StopIteration as retour:
print(retour.value)
Et là paf, une erreur :
2.
3.
4.
Traceback (most recent call last):
File "/home/julien/Bureau/tuto async/ref-8.py", line 38, in <module>
generateur.send(lettre)
TypeError: can't send non-None value to a just-started generator
Impossible d'envoyer une valeur ! Pourquoi ? Parce que
yield
fonctionne « de droite à gauche », c'est-à-dire qu'il met d'abord en pause la fonction sous forme de générateur puis envoie une donnée éventuellement fournie (ou
None
en son absence) avant d'en recevoir une (ou
None
en son absence). Lui demander de transmettre une donnée avant même une première mise en pause n'est pas admis et ne peut pas l'être, car aucun
yield
n'a été encore rencontré et donc aucune portion de code n'a été exécutée.
Le code correct est donc :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
18.
def Afficher():
premiere_fois = True
while True:
lettre = yield ("je démarre" if premiere_fois else None)
if lettre is None:
return "bonjour"
else:
print(lettre)
premiere_fois = False
try:
alphabet = ["a","b","c","d","e","f","g","h","i"]
generateur = Afficher()
print(next(generateur))
for lettre in alphabet:
generateur.send(lettre)
except StopIteration as retour:
print(retour.value)
Et là vous me direz : moi je veux recevoir et envoyer. C'est possible ? Testons ! Changeons une portion du code :
2.
3.
4.
5.
6.
7.
try:
alphabet = ["a","b","c","d","e","f","g","h","i"]
generateur = Afficher()
for lettre in alphabet:
print(next(generateur))
except StopIteration as retour:
print(retour.value)
… donnera :
2.
je démarre
bonjour
Tiens, le « bonjour » revient alors qu'il avait disparu : logique, comme je n'envoie pas
None
dans mon
try
/
except
, le générateur n'est jamais arrêté et donc l'exception n'est pas levée… Cette erreur, discrète et volontaire dans ce tutoriel, illustre la difficulté parfois à trouver les coquilles des scripts : l'asynchronisme ne se débogue pas aussi simplement que le séquentiel/synchrone.
2.
3.
4.
5.
6.
7.
8.
9.
try:
alphabet = ["a","b","c","d","e","f","g","h","i"]
generateur = Afficher()
for lettre in alphabet:
print(next(generateur))
except StopIteration as retour:
print(retour.value)
finally:
print("fin")
Donnera
2.
3.
je démarre
bonjour
fin
Logique ! Nous devons donc respecter les étapes d'appel et, dans notre cas, d'arrêt de la boucle while True dans Afficher(), pour réaliser totalement le script :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
18.
19.
20.
21.
def Afficher():
premiere_fois = True
while True:
lettre = yield ("je démarre" if premiere_fois else "je continue")
if lettre is None:
return "bonjour"
else:
print(lettre)
premiere_fois = False
try:
alphabet = ["a","b","c","d","e","f","g","h","i"]
generateur = Afficher()
print(next(generateur))
for lettre in alphabet:
print(generateur.send(lettre))
generateur.send(None)
except StopIteration as retour:
print(retour.value)
finally:
print("fin")
… donnera :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
18.
19.
20.
21.
je démarre
a
je continue
b
je continue
c
je continue
d
je continue
e
je continue
f
je continue
g
je continue
h
je continue
i
je continue
bonjour
fin
Avec un
yield from
, pas de changement de comportement :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
18.
19.
20.
21.
22.
23.
24.
25.
def Afficher():
premiere_fois = True
while True:
lettre = yield ("je démarre" if premiere_fois else "je continue")
if lettre is None:
return "bonjour"
else:
print(lettre)
premiere_fois = False
def proxy():
r = yield from Afficher()
return r
try:
alphabet = ["a","b","c","d","e","f","g","h","i"]
generateur = proxy()
print(next(generateur))
for lettre in alphabet:
print(generateur.send(lettre))
generateur.send(None)
except StopIteration as retour:
print(retour.value)
finally:
print("fin")
… donnera (toujours) ;
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
18.
19.
20.
21.
je démarre
a
je continue
b
je continue
c
je continue
d
je continue
e
je continue
f
je continue
g
je continue
h
je continue
i
je continue
bonjour
fin
III. Le début de l'asynchronisme : la liste des tâches▲
Probablement avez-vous deviné où je souhaite en venir. Si vous n'avez pas parfaitement saisi les paragraphes précédents, arrêtez-vous là pour l'instant. Continuer risque de vous rendre la tâche plus délicate encore. Car jusqu'à présent, notre code s'exécutait de manière linéaire, prévisible et surtout séquentielle : une fonction à chaque moment s'exécute dans un ordre bien arrêté.
Désormais nous passons à la vitesse supérieure : nous ne sommes plus tout à fait dans le séquentiel, mais pas encore pleinement dans l'asynchronisme. Nous utiliserons les principes vus plus haut pour créer un ordonnateur de tâches, c'est-à-dire un gestionnaire de générateurs. Au début faisons simple : chaque tâche doit être exécutée au plus tôt et, une fois terminée, elle est retirée de la liste ; sinon elle est ajoutée à la liste pour se poursuivre ultérieurement. Une fois la liste vide, nous pouvons arrêter le script. Cette liste est, en langage informatique, une pile telle que l'on peut la concevoir comme une pile de documents (ou de linge à repasser…).
Évidemment, notre exemple n'est que partiellement (a)synchrone : finalement, l'ensemble du script repose sur un code qui est bloquant et n'a pas le principe des promesses que nous verrons plus loin. Or un des principes de l'asynchronisme est d'être non bloquant - c'est-à-dire qu'une instruction n'en retarde pas une autre - et de permettre d'organiser ces tâches en groupes.
Notre gestionnaire simple, sans gestion des erreurs (elles sont juste affichées) et sans gestion des retours, donne pourtant déjà un outil assez puissant :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
18.
19.
20.
21.
22.
23.
24.
25.
26.
27.
28.
29.
30.
31.
32.
33.
34.
35.
36.
37.
38.
39.
40.
import types # pour reconnaître l'objet generator ; module par défaut dans Python
class Gestionnaire:
taches = []
def __init__(self):
pass
def tache(self, fct, args):
self.taches.append((
fct,
args
))
def lancer(self):
print("---\nGestionnaire : voici vos tâches au démarrage...")
print(self.taches)
print("---")
while len(self.taches)>0:
fct, args = self.taches.pop(0)
if isinstance(fct, types.GeneratorType):
try:
next(
fct
)
self.tache(
fct,
args
)
except StopIteration:
pass
elif callable(fct):
try:
self.tache(
fct( args),
args
)
except Exception as err:
print(fct, err)
Nous allons maintenant additionner ensemble tous les nombres entre 0 et 100 000. Cela correspond à :
… en découpant notre calcul en portions. Si vous connaissez ce concept, il s'agit des
workers
que l'on trouve désormais un peu partout (si vous ne connaissez pas, ce n'est pas grave, mais lisez quand même la définition pour en saisir les principes).
Ne vous préoccupez pas des performances pour l'instant, ça risque de prendre du temps, mais ce n'est pas l'essentiel :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
18.
19.
20.
21.
22.
23.
24.
25.
26.
27.
28.
29.
30.
31.
32.
33.
34.
35.
36.
class CalculsTresLong:
a_traiter = list(range(0,100000))
total = 0
nbre_max_travailleurs = 10
travailleurs = []
def lancer_travailleurs(self, gestionnaire_taches):
print("j'ai besoin de", self.nbre_max_travailleurs, "travailleurs")
nbre_travailleurs = 0
while nbre_travailleurs<10:
self.travailleurs.append(
gestionnaire_taches.tache(
self.traiter_portion,
nbre_travailleurs
)
)
print("travailleur n°", nbre_travailleurs, "a été lancé")
nbre_travailleurs = len(self.travailleurs)
print("on débute le travail")
gestionnaire_taches.lancer()
print("on a fini le travail")
def traiter_portion(self, numero_travailleur):
print("je suis le travailleur n°", numero_travailleur)
total_traitees = 0
while len(self.a_traiter)>0:
self.total += self.a_traiter.pop(0)
total_traitees += 1
yield
print("j'ai fini et je suis le travailleur n°", numero_travailleur, "(", total_traitees, " portions traitées)")
gestionnaire = Gestionnaire()
calculs = CalculsTresLong()
calculs.lancer_travailleurs(gestionnaire)
… donnera :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
18.
19.
20.
21.
22.
23.
24.
25.
26.
27.
28.
29.
30.
31.
32.
33.
34.
35.
36.
37.
38.
j'ai besoin de 10 travailleurs
travailleur n° 0 a été lancé
travailleur n° 1 a été lancé
travailleur n° 2 a été lancé
travailleur n° 3 a été lancé
travailleur n° 4 a été lancé
travailleur n° 5 a été lancé
travailleur n° 6 a été lancé
travailleur n° 7 a été lancé
travailleur n° 8 a été lancé
travailleur n° 9 a été lancé
on débute le travail
---
Gestionnaire : voici vos tâches au démarrage...
[(<bound method CalculsTresLong.traiter_portion of <__main__.CalculsTresLong object at 0xb5b6cf2c>>, (0,)), (<bound method CalculsTresLong.traiter_portion of <__main__.CalculsTresLong object at 0xb5b6cf2c>>, (1,)), (<bound method CalculsTresLong.traiter_portion of <__main__.CalculsTresLong object at 0xb5b6cf2c>>, (2,)), (<bound method CalculsTresLong.traiter_portion of <__main__.CalculsTresLong object at 0xb5b6cf2c>>, (3,)), (<bound method CalculsTresLong.traiter_portion of <__main__.CalculsTresLong object at 0xb5b6cf2c>>, (4,)), (<bound method CalculsTresLong.traiter_portion of <__main__.CalculsTresLong object at 0xb5b6cf2c>>, (5,)), (<bound method CalculsTresLong.traiter_portion of <__main__.CalculsTresLong object at 0xb5b6cf2c>>, (6,)), (<bound method CalculsTresLong.traiter_portion of <__main__.CalculsTresLong object at 0xb5b6cf2c>>, (7,)), (<bound method CalculsTresLong.traiter_portion of <__main__.CalculsTresLong object at 0xb5b6cf2c>>, (8,)), (<bound method CalculsTresLong.traiter_portion of <__main__.CalculsTresLong object at 0xb5b6cf2c>>, (9,))]
---
je suis le travailleur n° 0
je suis le travailleur n° 1
je suis le travailleur n° 2
je suis le travailleur n° 3
je suis le travailleur n° 4
je suis le travailleur n° 5
je suis le travailleur n° 6
je suis le travailleur n° 7
je suis le travailleur n° 8
je suis le travailleur n° 9
j'ai fini et je suis le travailleur n° 0 ( 10000 portions traitées)
j'ai fini et je suis le travailleur n° 1 ( 10000 portions traitées)
j'ai fini et je suis le travailleur n° 2 ( 10000 portions traitées)
j'ai fini et je suis le travailleur n° 3 ( 10000 portions traitées)
j'ai fini et je suis le travailleur n° 4 ( 10000 portions traitées)
j'ai fini et je suis le travailleur n° 5 ( 10000 portions traitées)
j'ai fini et je suis le travailleur n° 6 ( 10000 portions traitées)
j'ai fini et je suis le travailleur n° 7 ( 10000 portions traitées)
j'ai fini et je suis le travailleur n° 8 ( 10000 portions traitées)
j'ai fini et je suis le travailleur n° 9 ( 10000 portions traitées)
on a fini le travail
4999950000
Plusieurs observations :
- nous pouvons créer des générateurs de méthodes, sans que cela pose problème. En effet, notre générateur part d'une méthode et celle-ci est liée à un objet (notamment grâce au passage de références). Pas besoin de s'occuper du moindre scope (c'est-à-dire de la portée des variables) et comme il n'y a qu'une (et une seule) exécution à la fois, il n'y a aucun de problème de concurrence dans l'accès à une ressource ;
- le résultat est cohérent : il n'y a pas eu de doublons, pas de perte. Aucune erreur n'a été générée (en dehors des StopIteration prévues) ;
- il y a une répartition « naturelle » des charges sur les travailleurs, en paquet identique. Du coup, il en ressort une impression que l'asynchrone voulu… est tout à fait synchrone ;
-
si j'ajoute quelque part un
time.sleep()
(pour simuler une attente IO, par exemple), c'est toute la boucle qui est arrêtée en même temps.
Modifions donc pour rendre la chose plus aléatoire. Chaque travailleur ne pourra traiter désormais qu'un nombre de tâches limité et propre à ce même travailleur. La méthode lancer_travailleurs() devra donc impérativement en lancer de nouveaux tant que c'est nécessaire - sans dépasser le total fixé.
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
18.
19.
20.
21.
22.
23.
24.
25.
26.
27.
28.
29.
30.
31.
32.
33.
34.
35.
36.
37.
38.
39.
40.
41.
42.
43.
44.
45.
46.
47.
class CalculsTresLong:
a_traiter = list(range(0,100000))
total = 0
nbre_max_travailleurs = 10
travailleurs = {}
def lancer_travailleurs(self, gestionnaire_taches):
numero = 0
while True:
while len(self.travailleurs)<self.nbre_max_travailleurs:
print("je dois ajouter un travailleur ; n°", numero)
self.travailleurs[numero] = gestionnaire_taches.tache(
self.traiter_portion,
numero
)
numero += 1
yield
yield
if len(self.a_traiter)==0:
break
def superviser(self, gestionnaire_taches):
print("superviseur : on débute le travail")
gestionnaire_taches.tache(
self.lancer_travailleurs,
gestionnaire_taches
)
gestionnaire_taches.lancer()
print("superviseur : on a fini le travail")
def traiter_portion(self, numero):
max_portions = random.randint(1, 5000)
print("je suis le travailleur n°", numero, " et je peux traiter", max_portions, "portions")
total_traitees = 0
while len(self.a_traiter)>0 and total_traitees<=max_portions:
self.total += self.a_traiter.pop(0)
total_traitees += 1
yield
print("j'ai fini et je suis le travailleur n°", numero, " ; je me retire de la liste des travailleurs")
del self.travailleurs[numero]
gestionnaire = Gestionnaire()
calculs = CalculsTresLong()
calculs.superviser(gestionnaire)
print(calculs.total)
… donnera :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
18.
19.
20.
21.
22.
23.
24.
25.
26.
27.
28.
29.
30.
31.
32.
33.
34.
35.
36.
37.
38.
39.
40.
41.
42.
43.
44.
45.
46.
47.
48.
49.
50.
51.
52.
53.
superviseur : on débute le travail
---
Gestionnaire : voici vos tâches au démarrage...
[(<bound method CalculsTresLong.lancer_travailleurs of <__main__.CalculsTresLong object at 0xb5ba3f4c>>, (<__main__.Gestionnaire object at 0xb5ba3f2c>,))]
---
je dois ajouter un travailleur ; n° 0
je dois ajouter un travailleur ; n° 1
je suis le travailleur n° 0 et je peux traiter 3187 portions
je dois ajouter un travailleur ; n° 2
je suis le travailleur n° 1 et je peux traiter 4877 portions
je dois ajouter un travailleur ; n° 3
je suis le travailleur n° 2 et je peux traiter 2065 portions
je dois ajouter un travailleur ; n° 4
je suis le travailleur n° 3 et je peux traiter 2485 portions
je dois ajouter un travailleur ; n° 5
je suis le travailleur n° 4 et je peux traiter 1674 portions
je dois ajouter un travailleur ; n° 6
je suis le travailleur n° 5 et je peux traiter 3755 portions
je dois ajouter un travailleur ; n° 7
je suis le travailleur n° 6 et je peux traiter 1520 portions
je dois ajouter un travailleur ; n° 8
je suis le travailleur n° 7 et je peux traiter 2567 portions
je dois ajouter un travailleur ; n° 9
je suis le travailleur n° 8 et je peux traiter 4708 portions
je suis le travailleur n° 9 et je peux traiter 116 portions
j'ai fini et je suis le travailleur n° 9 ; je me retire de la liste des travailleurs
je dois ajouter un travailleur ; n° 10
je suis le travailleur n° 10 et je peux traiter 2235 portions
j'ai fini et je suis le travailleur n° 6 ; je me retire de la liste des travailleurs
je dois ajouter un travailleur ; n° 11
je suis le travailleur n° 11 et je peux traiter 3420 portions
j'ai fini et je suis le travailleur n° 4 ; je me retire de la liste des travailleurs
je dois ajouter un travailleur ; n° 12
[…]
je suis le travailleur n° 44 et je peux traiter 4738 portions
j'ai fini et je suis le travailleur n° 24 ; je me retire de la liste des travailleurs
je dois ajouter un travailleur ; n° 45
je suis le travailleur n° 45 et je peux traiter 1329 portions
j'ai fini et je suis le travailleur n° 28 ; je me retire de la liste des travailleurs
je dois ajouter un travailleur ; n° 46
je suis le travailleur n° 46 et je peux traiter 1448 portions
j'ai fini et je suis le travailleur n° 46 ; je me retire de la liste des travailleurs
j'ai fini et je suis le travailleur n° 30 ; je me retire de la liste des travailleurs
j'ai fini et je suis le travailleur n° 34 ; je me retire de la liste des travailleurs
j'ai fini et je suis le travailleur n° 35 ; je me retire de la liste des travailleurs
j'ai fini et je suis le travailleur n° 38 ; je me retire de la liste des travailleurs
j'ai fini et je suis le travailleur n° 41 ; je me retire de la liste des travailleurs
j'ai fini et je suis le travailleur n° 42 ; je me retire de la liste des travailleurs
j'ai fini et je suis le travailleur n° 43 ; je me retire de la liste des travailleurs
j'ai fini et je suis le travailleur n° 44 ; je me retire de la liste des travailleurs
j'ai fini et je suis le travailleur n° 45 ; je me retire de la liste des travailleurs
superviseur : on a fini le travail
4999950000
Nous pouvons le constater, notre code ne s'exécute plus du tout de la même manière et n'est plus totalement prédictible : il y a une part de hasard dans le nombre de portions exécutées par chaque travailleur. Le nombre total de travailleurs nécessaires, comme l'ordonnancement, se complexifie et devient non pas erratique (c'est-à-dire sans cohérence) mais imprévisible (c'est-à-dire sans possibilité d'être connu à l'avance).
Relancez le code, vous n'aurez pas le même nombre de travailleurs - sans que celui-ci ne tombe en dessous de 20 (car la part maximum de travail supporté est au maximum de 5000 portions, soit
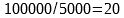 ).
).
III-A. Tâche + temps = agenda ▲
Vous vous disiez que le plus dur était passé ? Eh bien, non ! Heureusement pour vous, on ne change rien dans les mots-clés et les concepts : nous poussons le raisonnement un peu plus loin.
Tout d'abord en intégrant une dimension temporelle à nos tâches. Pour l'instant, c'est l'ordre d'arrivée qui compte et la plus ancienne (c'est-à-dire celle qui part de 0 dans la liste d'attente) qui est traitée en premier. Sans autre possibilité de la différer dans le temps. Attention, il ne s'agit pas de la conditionner à un état ou à une autre fonction, juste… d'attendre.
Et attendre c'est facile avec
yield
: il suffit d'avoir une boucle qui compare deux valeurs de temps. Si la valeur est négative, il faut encore attendre. Si c'est positif, on peut continuer. À chaque itération, on teste cette simple condition. Vous savez ce qu'est une liste de tâches ordonnée dans le temps ? Un agenda. Alors appelons notre variable « temps » comme cela !
Si l'on attend, il faudra aussi avoir un moyen d'annuler cette tâche qui sera réalisée à l'instant voulu. Notre ajout d'une tâche va donc devoir générer un numéro unique (ici un simple compteur incrémentiel).
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
18.
19.
20.
21.
22.
23.
24.
25.
26.
27.
28.
29.
30.
31.
32.
33.
34.
35.
36.
37.
38.
39.
40.
41.
42.
43.
44.
45.
46.
47.
48.
49.
50.
51.
52.
53.
54.
class Gestionnaire:
__numero__ = -1 # pour que la première tâche soit à 0
taches = []
def __init__(self):
pass
@property
def numero(self):
self.__numero__ += 1
return self.__numero__
def tache(self, numero, duree, fct, args):
numero = self.numero if numero is None else numero # faire appel à cette propriété simulée "self.numero" (qui en réalité une méthode de l'objet, nous donne la possibilité de faire automatiquement l'incrémentation : il n'y aura donc jamais de doublon
agenda = [(duree if isinstance(duree, int) else 0), 0]
self.taches.append((
numero,
agenda,
fct,
args
))
return numero
def lancer(self):
demarrage = time.time()
while len(self.taches)>0:
numero, agenda, fct, args = self.taches.pop(0)
if isinstance(fct, types.GeneratorType):
try:
next(
fct
)
self.tache(
numero,
agenda[1],
fct,
args
)
except StopIteration:
pass
elif callable(fct):
try:
duree, debut = agenda
if debut==0:
debut = time.time()
self.tache(
numero,
[duree, debut],
fct( args) if (debut-demarrage)>=duree else fct, # on exécute... ou pas
args
)
except Exception as err:
print(fct, err)
Testons maintenant avec des fonctions retardées et trèèèès lentes… au passage et avant de les lancer dans votre console, devinez combien de temps va durer au total ce script ?
Au moins six secondes,
car fct2() fera appel à fct1() qui va durer au moins quatre secondes, auxquelles s'ajoute deux secondes supplémentaires. Comme fct1() appelée directement, s'exécute « en parallèle », sa durée ne s'ajoute pas et son retardement d'une seconde ne change rien.
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
18.
19.
20.
21.
22.
23.
24.
25.
26.
27.
28.
29.
30.
31.
32.
33.
34.
35.
36.
37.
38.
39.
40.
41.
42.
43.
def attendre(duree):
depart = time.time()
while (time.time()-depart)<duree:
yield
def fct1(appel_par):
print("fct1 : j'ai commencé ; appelée par", appel_par)
yield from attendre(1) # attente d'1 seconde
print("fct1 : j'en suis au milieu ; appelée par", appel_par)
yield from attendre(3) # attente de 3 seconde
print("fct1 : j'ai fini ; appelée par", appel_par)
def fct2():
print("fct2 : j'ai commencé")
yield from fct1("fct2")
print("fct2 : j'en suis au milieu")
yield from attendre(2)
print("fct2 : j'ai fini")
def fct3():
print("je n'attends rien et je ne suis même pas un générateur")
debut = time.time()
gestionnaire = Gestionnaire()
gestionnaire.tache(
None, # on laisse le script assigné le bon numéro
1, # on retarde d'une seconde
fct1,
"personne !"
)
gestionnaire.tache(
None,
0, # on exécute dès que possible
fct2
)
gestionnaire.tache(
None,
0,
fct3
)
gestionnaire.lancer()
fin = time.time()
print(fin-debut, "secondes")
… donnera (lentement) …
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
fct3 : je n'attends rien et je ne suis même pas un générateur
fct2 : j'ai commencé
fct1 : j'ai commencé ; appelée par fct2
fct1 : j'ai commencé ; appelée par personne !
fct1 : j'en suis au milieu ; appelée par fct2
fct1 : j'en suis au milieu ; appelée par personne !
fct1 : j'ai fini ; appelée par fct2
fct2 : j'en suis au milieu
fct1 : j'ai fini ; appelée par personne !
fct2 : j'ai fini
6.21833872795105 secondes
Sans l'asynchronisme, nous aurions dû attendre un peu plus de 11 secondes
, soit l'addition de l'ensemble des temps d'attente de toutes les fonctions. Notre script paraît donc « deux fois plus rapide » (nous verrons dans le chapitre suivant que ce n'est pas tout à fait vrai).
III-B. Agenda + promesses = asynchronisme ▲
Voilà à la dernière étape de la complexification. Humainement, nous sommes aux limites de la pensée complexe, car à partir de maintenant, la prédictibilité « naturelle » et le nombre d'états possibles pour notre gestionnaire de tâches (qui n'a pourtant pas pris une ampleur démesurée !) dépasseront ce qu'il est possible de coucher sur le papier.
En d'autres termes, l'asynchronisme devient une boîte noire, une forme de théorie de ce que l'on souhaite faire et qu'il est difficile de visualiser dans son ensemble et dans le temps. Seules la pratique et l'expérience de son propre code renseignent. Même quelques lignes de codes peuvent devenir un enfer en cas de pépin ! Son utilisation, même si elle est parfois tentante, doit être raisonnable.
La « promesse » que l'on rajoute, c'est un principe de
call-back
(fonctions de rappel en bon français) et d'états non encore définis. C'est-à-dire que nous aurons des fonctions ordonnées dans chaque tâche (en gros l'organisation interne de la tâche) avec la possibilité pour ces mêmes tâches, individuellement, d'avoir accès à des états qui ne peuvent pas être connus au moment où elles sont appelées. Le tout forme un objet « promesse » qui est étendu naturellement par les fonctions de rappel, qui ont pour paramètre ce même objet.
Impossible de traiter des données non encore définies ? Presque : un générateur est après tout une promesse d'un traitement, que l'on appelle au moment où on le souhaite. Les notions sont similaires et offrent une grande liberté dans la pratique.
Dans notre cas, la promesse d'un traitement se lie à l'affectation d'un résultat : ma promesse enregistre des fonctions à appeler lorsque le résultat est connu et, dans l'attente, se retourne elle-même pour être « transportée » ailleurs si nécessaire. On échange donc pas une valeur à proprement parler, mais une sorte de signature, d'enregistrement, de ce quelle sera. Là encore, c'est le passage par référence et non par valeur (on stocke la référence d'une valeur et non la valeur elle-même), qui permet un tel résultat.
Dès que la promesse est réalisée, c'est-à-dire qu'on lui assigne son état final, on déclenche alors chacune des fonctions qui lui est associée et toutes les variables qui lui sont attachées, peuvent disposer du résultat de la promesse.
Dès lors on peut imaginer que la tâche est elle-même une promesse et que le gestionnaire de tâches n'est finalement qu'un ordonnateur non pas de tâches, mais de promesses qui seront réalisées. Ce sont aux promesses d'organiser les tâches au travers du gestionnaire.
Testons et tout d'abord modifions notre gestionnaire. Il prendra désormais de manière optionnelle un numéro, une durée d'attente et une fonction de rappel. Cette fonction de rappel sera réalisée après la réalisation de la fonction initiale de tâche et, l'une comme l'autre, peuvent être ou non des générateurs.
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
18.
19.
20.
21.
22.
23.
24.
25.
26.
27.
28.
29.
30.
31.
32.
33.
34.
35.
36.
37.
38.
39.
40.
41.
42.
43.
44.
45.
46.
47.
48.
49.
50.
51.
52.
53.
54.
55.
56.
57.
58.
59.
60.
61.
62.
63.
64.
65.
66.
67.
68.
69.
70.
import types
import time
class Gestionnaire:
__numero__ = -1 # pour que la première tâche soit à 0
taches = []
def __init__(self):
pass
@property
def numero(self):
self.__numero__ += 1
return self.__numero__
def tache(self, fct, args, numero=None, duree=0, rappel=None):
numero = self.numero if numero is None else numero
agenda = [(duree if isinstance(duree, int) else 0), 0]
self.taches.append((
numero,
agenda,
rappel,
fct,
args
))
return numero
def lancer(self):
demarrage = time.time()
while len(self.taches)>0:
poursuite = False
numero, agenda, rappel, fct, args = self.taches.pop(0)
if isinstance(fct, types.GeneratorType):
try:
next(
fct
)
poursuite = True
except StopIteration:
if callable(rappel):
fct = rappel
rappel = None
args = ()
poursuite = True
except Exception as err:
print("! err : ", fct, err)
elif callable(fct):
try:
duree, debut = agenda
if debut==0:
debut = time.time()
if (debut-demarrage)>=duree:
fct = fct( args)
poursuite = True
except Exception as err:
print("! err : ", fct, err)
elif callable(rappel):
fct = rappel
rappel = None
args = ()
poursuite = True
if poursuite:
self.taches.append((
numero,
[duree, debut],
rappel,
fct,
args
))
Pour la classe Promesse, c'est facile : on déclare un gestionnaire, une possibilité d'ajouter des fonctions de rappel pour la promesse et on affecte une valeur comme résultat de celle-ci. Cette « réalisation » enclenche une méthode qui insère, comme un itérable, les fonctions de rappels les unes après les autres au sein du gestionnaire, en prenant en rappel de tâche la méthode __realisation__ de la promesse elle-même.
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
18.
19.
20.
21.
22.
23.
24.
25.
26.
27.
28.
29.
30.
31.
32.
33.
class Promesse:
gestionnaire = None
def __init__(self, gestionnaire):
self.gestionnaire = gestionnaire
self.rappels = []
self.resultatConnu = False
self.realisation = False
def rappel(self, fct):
if self.resultatConnu is False:
self.rappels.append(
fct
)
def realiser(self, resultat):
self.resultatConnu = True
self.resultat = resultat
if gestionnaire is not None:
gestionnaire.tache(
self.__realisation__
)
def __realisation__(self):
if len(self.rappels)>0:
gestionnaire.tache(
self.rappels.pop(0),
self,
rappel = self.__realisation__ # en somme : quand t'as fini, tu reviens ici voir s'il y a d'autres trucs à faire
)
else:
self.realisation = True
Pour la partie de pur test, quelques fonctions bateau (pouvant être ou non des générateurs) mais dont il est difficile à deviner l'enchaînement au premier abord avec deux promesses qui se chevauchent et se complètent.
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
18.
19.
20.
21.
22.
23.
24.
25.
26.
27.
28.
29.
30.
31.
32.
33.
34.
35.
36.
37.
38.
39.
40.
41.
42.
43.
44.
45.
46.
47.
48.
49.
50.
51.
52.
53.
54.
def attendre(duree):
print("{attendre}")
depart = time.time()
while (time.time()-depart)<duree:
yield
def fct1(objPromesse):
print("{fct1}")
objPromesse.resultat = "je suis fct1"
def fct2(objPromesse):
print("{fct2}")
print(objPromesse.resultat)
def fct3(objPromesse):
print("{fct3}")
objPromesse.resultat = "je suis fct3"
yield from attendre(1)
def fct4(objPromesse):
print("{fct4}")
p1 = objPromesse.resultat
print("la fct4 de p2 vous dit que : ", p1.resultat)
def promesse1(gestionnaire):
print("{promesse1}")
p1 = Promesse(gestionnaire)
p1.rappel(
fct1
)
p1.rappel(
fct2
)
return p1
def realisetoi():
p1 = promesse1(gestionnaire)
yield from attendre(1)
p1.realiser("ok pour p2")
p2 = Promesse(gestionnaire)
p1.rappel(
fct3
)
p2.rappel(
fct4
)
yield from attendre(2)
p2.realiser(p1)
gestionnaire = Gestionnaire()
gestionnaire.tache(
realisetoi
)
gestionnaire.lancer()
… donnera :
2.
3.
4.
5.
6.
7.
8.
{promesse1}
{attendre}
{attendre}
{fct1}
{fct2}
je suis fct1
{fct4}
la fct4 de p2 vous dit que : je suis fct1
Surprise ! Si vous avez suivi la déclaration des fonctions de rappel pour p1, fct3() aurait dû modifier la valeur de p1 par « je suis fct3 ».
Pourquoi n'est-ce pas le cas ? Simplement la promesse ayant déjà été réalisée, on ne peut ajouter de fonction de rappel (il s'agit d'une protection logique, afin qu'il n'y ait pas une fonction qui ne soit jamais appelée - comme si elle était « oubliée »). Une exception devrait être lancée - mais par souci de pédagogie, j'ai préféré laisser cette « erreur » ne pas être gérée/affichée et le signaler.
Imaginer ce code désormais en temps réel, avec des centaines de promesses, contenant parfois des dizaines de tâches, des rappels dans tous les sens et bien sûr des liaisons de promesses entre elles…
Bienvenue dans l'asynchronisme !
IV. Au quotidien▲
IV-A. Quels cas d'usage pour un tel bazar ?▲
Bravo ! Vous avez désormais passé le plus dur. Les principaux concepts ont été expliqués (et j'espère compris). Nous allons pouvoir mettre en œuvre la mise en code standard de l'asynchronisme.
Cependant et avant de continuer, tordons le cou à quelques idées reçues et démontrons quelques hypothèses.
IV-A-1. « L'asynchronisme, c'est plus rapide… » ▲
Vrai et faux : faux, car le script n'est pas plus rapide. Il leurre son utilisateur, en offrant davantage de possibilités en
nombre total
des tâches gérées en même temps, sans perdre de temps à attendre l'une au détriment des autres. Cependant celles-ci ne sont pas nécessairement plus rapides individuellement, voire les performances se dégradent considérablement si l'usage est erratique.
Exemple : je souhaite deux fonctions, qui feront 1000 itérations (de 0 à 1000) chacune. La première additionne un nombre à la valeur retournée par l'autre, qui elle-même fait une opération de division puis d'addition. En similicode, ça donne :
2.
3.
pour a de 0 à 1000 :
pour b de 0 à 1000 :
a = a + (b/1000)
Si l'on reprend le fonctionnement des mots-clés
yield
et
yield from
évoqués plus haut, mon code Python donnerait les deux scripts suivants, avec le nécessaire à l'identique pour mesurer la performance avec 11 appels de mon similicode :
script séquentiel :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
18.
19.
20.
21.
22.
23.
24.
25.
26.
import time
resultats = []
for _ in range(0,10):
debut = time.time()
def R1(y):
for i in range(0, 1000):
y += (i/1000)
return y
def R2():
y = 0
for i in range(0, 1000):
y += R1(i)
return y
resultat = R2()
fin = time.time()
resultats.append(fin - debut)
print(sum(resultats), "secondes")
… script avec appel de
yield
:
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
18.
19.
20.
21.
22.
23.
24.
25.
26.
27.
28.
29.
30.
31.
32.
33.
34.
import time
resultats = []
for _ in range(0,10):
debut = time.time()
def R1(y):
for i in range(0, 1000):
y += (i/1000)
yield
return y
def R2():
y = 0
for i in range(0, 1000):
y += yield from R1(i)
return y
try:
g = R2()
while True:
next(g)
except StopIteration as r:
resultat = r.value
finally:
pass
fin = time.time()
resultats.append(fin - debut)
print(sum(resultats), "secondes")
Dans notre cas, l'intérêt est de toute façon tout à fait inexistant de faire appel à
yield
: le code n'est plus efficace et pire, bien moins lisible ! Sans surprise les résultats sont douloureux et donnent la palme de l'efficacité au séquentiel :
2.
3.
julien@devJG2:~/Bureau/tuto async$ python3 ref-1.py && python3 ref-2.py
3.371870994567871 secondes
9.662042140960693 secondes
Pour autant, dans des cas plus complexes et plus réalistes, la différence est parfois plus ténue, car il peut y avoir des « goulots » lors des lectures et écritures de fichiers que l'asynchrone, quant à lui, gérera très bien. Cependant l'insertion de l'asynchronisme dans un code synchrone (cela reste possible avec quelques
hacks
grâce à une utilisation ingénieuse des
threads
), ou géré sur une multitude de processus individuels (qui demandent même à communiquer grâce aux
sockets
, donc avec un temps de latence à gérer…), n'offre pas guère de souplesse. Il faut donc mesurer l'impact général et éviter les pièges.
Le plus souvent, le passage à l'asynchronisme impose une refactorisation/réécriture de tout son code. Nous verrons que les nouvelles versions de Python tentent de gommer cet aspect.
IV-A-2. « …surtout pour le web !▲
Un des pièges est de raisonner comme seulement « serveur » d'un traitement. C'est-à-dire de se fixer non comme le consommateur final de la donnée (le client), mais celui qui fait le lien, la crée ou la duplique (le serveur). Ainsi l'asynchronisme peut faire progresser fortement les performances d'un serveur (en démultipliant le nombre de clients servis) sans offrir nécessairement un temps plus court de réponse aux clients (or, c'est l'objectif).
Ainsi si ma requête de BDD met 0,5 seconde à s'exécuter, le serveur, plutôt qu'attendre, fera autre chose. C'est efficace certes, mais le client attendra toujours finalement 0,5 seconde de trop ! L'efficacité de l'asynchronisme tient donc à deux composants majeurs :
- sa complexité, qui rend souvent l'usage délicat, notamment pour la gestion des logs et des erreurs et ne s'arrête qu'à rendre « plus efficace » les temps d'attente et non de calculs ;
- sa pertinence si l'on se place comme usager final ou de traitement (si l'on est observateur de l'efficacité même d'une portion asynchrone, ou de l'ensemble dans laquelle cette portion évolue).
IV-A-3. « L'asynchronisme est une mode » ▲
Sûrement : les évolutions offertes par les nouveautés de Python poussent à en faciliter l'usage, parfois au détriment de l'intérêt. Mais une remarque telle que celle en titre est stupide, car Python n'est pas une mode et l'asynchronisme n'en est qu'une modalité.
L'asynchronisme répond au défi que provoque l'augmentation du nombre de processus indépendants qui communiquent entre eux, sur le Net, de l'utilisation des
sockets
, de gérer plus aisément l'écriture et la lecture de fichiers lourds, par portion ou non, alors que les
threads
ont des contraintes de charge (notamment le GIL -
global interpreter lock
).
Dit-on que
subprocess
, les
threads
ou le multiprocessing sont des modes ?
IV-A-4. « Il y a des frameworks tout prêts ; les développeurs de Python ont simplifié tout ça ; un tutoriel comme celui-là n'apporte rien »▲
Tant mieux si vous comprenez parfaitement toutes les subtilités tout de suite. Ce ne fut pas mon cas et, à l'image des forums de développez.com, le cas de beaucoup d'autres. Utiliser un outil que l'on ne comprend pas en informatique, c'est comme rouler en Porche sans permis. C'est possible, mais l'inexpérience est un facteur de risque. Votre débogage risque d'être incomplet, voire problématique, car vous ne saurez pas nécessairement quelle est véritablement l'erreur.
Et lorsque cette erreur n'en est pas une, mais un problème, même de conception, vous repenserez à ce tutoriel en vous demandant ce qui peut poser problème… Mieux vaut prévenir que guérir !
IV-B. Reprendre les bons termes, même si…▲
Jusqu'à présent, je vous ai épargné les termes anglophones volontairement. D'abord parce qu'il y a des faux-amis de traductions, qui peuvent mal aiguiller les non-anglophones. Pourtant il faudra travailler avec…
- Une fonction « mise en pause » avec un générateur pour la parcourir, c'est une coroutine. Le gestionnaire de tâches ou de promesses est une event loop - une boucle d'événements.
- Il est nécessaire, dans Python, par défaut, de lui signaler l'asynchronisme lors de la déclaration des fonctions qui seront des coroutines soit par un décorateur (type @asyncio.coroutine évoqué plus haut), soit par un mot-clé (async def). Lorsqu'une coroutine est appelée, il faut indiquer à Python que c'en est une soit par une fonction, soit par un mot-clé (await).
- Une event loop est toujours bloquante (ce qui est ironique, car finalement, c'est elle qui permet d'avoir du code dit « non bloquant » !). Il faut déclarer une liste de tâches arrêtée lorsque l'on travaille avec un event loop.
Vous noterez qu'il y a deux façons différentes de faire l'asynchronisme « moderne » : une version plus ancienne que l'on nomme asyncio, une bibliothèque devenue standard de Python, ainsi que les mots-clés async /await qui remplissent les mêmes fonctions de parcours automatique (gestion des StopIteration, etc.). Or il n'y a pas d'obligation, sinon pour des raisons de praticité et sur quelques points de performance, de ne passer que par eux : nous venons de faire tout un tutoriel sans !
Préférez toujours un code lisible, dans quel il est facile de comprendre, que des hauts niveaux d'abstraction qui certes, permettent une programmation plus rapide à écrire, mais n'offre pas toujours en retour une bonne vision de ce qu'un code lisible par l'humain devrait être. Les raisons qui poussent à l'utilisation de asyncio et du couple await/async, tournent souvent autour de la volonté de se rapprocher d'une écriture séquentielle. Cela induit trop souvent les personnes en erreur !
IV-C. Exemples connus d'async ▲
Si vous avez bien suivi ce tutoriel, les deux codes ci-dessous doivent vous être très parlants et sont tirés de la documentation officielle de Python :
…
grâce à un décorateur :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
import asyncio
@asyncio.coroutine
def slow_operation(n):
yield from asyncio.sleep(1)
print("Slow operation {} complete".format(n))
@asyncio.coroutine
def main():
yield from asyncio.wait([
slow_operation(1),
slow_operation(2),
slow_operation(3),
])
… grâce aux mots-clés :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
18.
19.
20.
loop = asyncio.get_event_loop()
loop.run_until_complete(main())
import asyncio
async def slow_operation(n):
await asyncio.sleep(1)
print("Slow operation {} complete".format(n))
async def main():
await asyncio.wait([
slow_operation(1),
slow_operation(2),
slow_operation(3),
])
loop = asyncio.get_event_loop()
loop.run_until_complete(main())
V. Fin▲
Voilà nous en sommes à la fin de ce tutoriel qui vous aura, je l'espère, permis de mieux comprendre ce qu'est l'asynchronisme. Volontairement, j'ai évité les seuls exemples liés à la programmation web/réseaux, pour concentrer l'attention sur ce que propose cette méthode de programmation plutôt qu'en circonscrire l'usage à des exemples maintes fois vus sur le web.
Il reste sur ce sujet encore tant à dire, notamment sur les décorateurs qui aident sacrément la vie du développeur et qu'utilise le module
asyncio
. C'est aussi le cas de certains modules particulièrement pointus, comme les « sélecteurs » pour les opérations de lecture IO, qui scrutent dans un cadre asynchrone, la possibilité ou non de récupérer du contenu et d'éviter un temps mort dans une tâche et de retarder l'ensemble.
Alors à une prochaine fois… ?
VI. Note de la rédaction de Developpez.com▲
Nous tenons à remercier Jacques_jean pour la relecture orthographique de ce tutoriel.